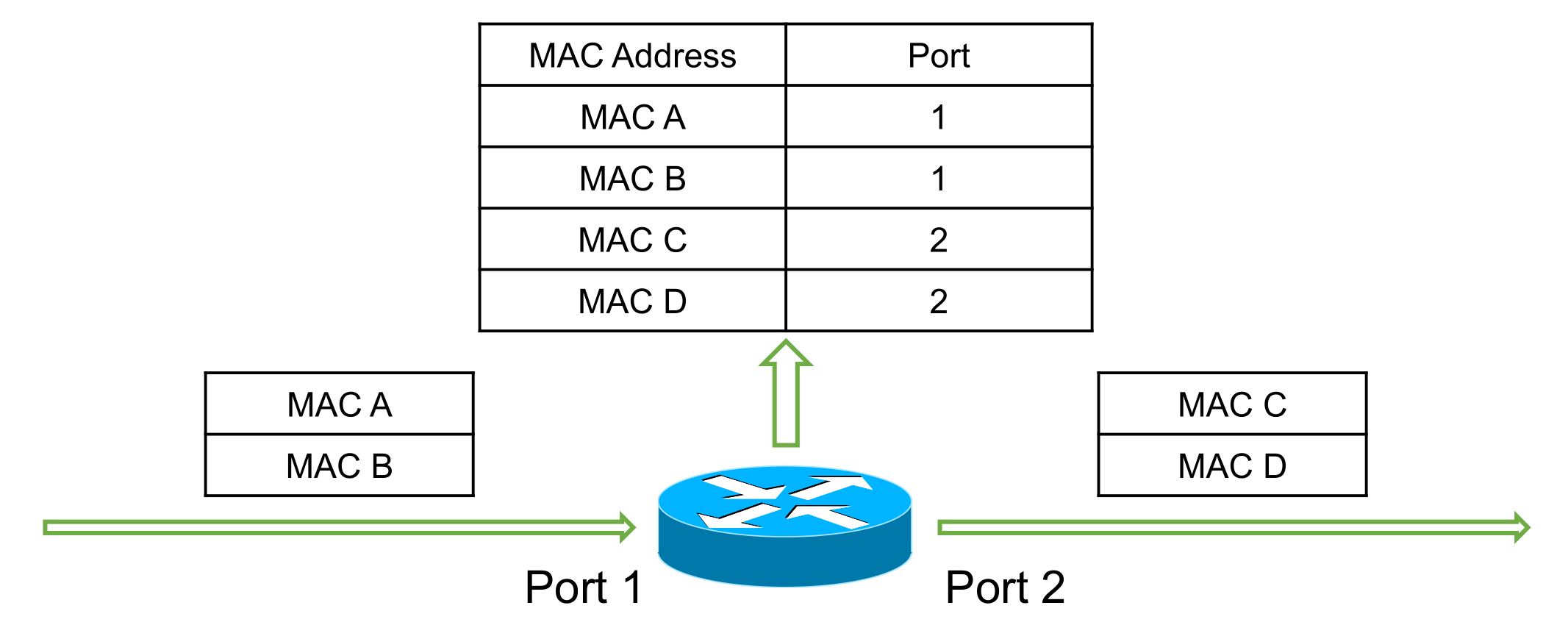
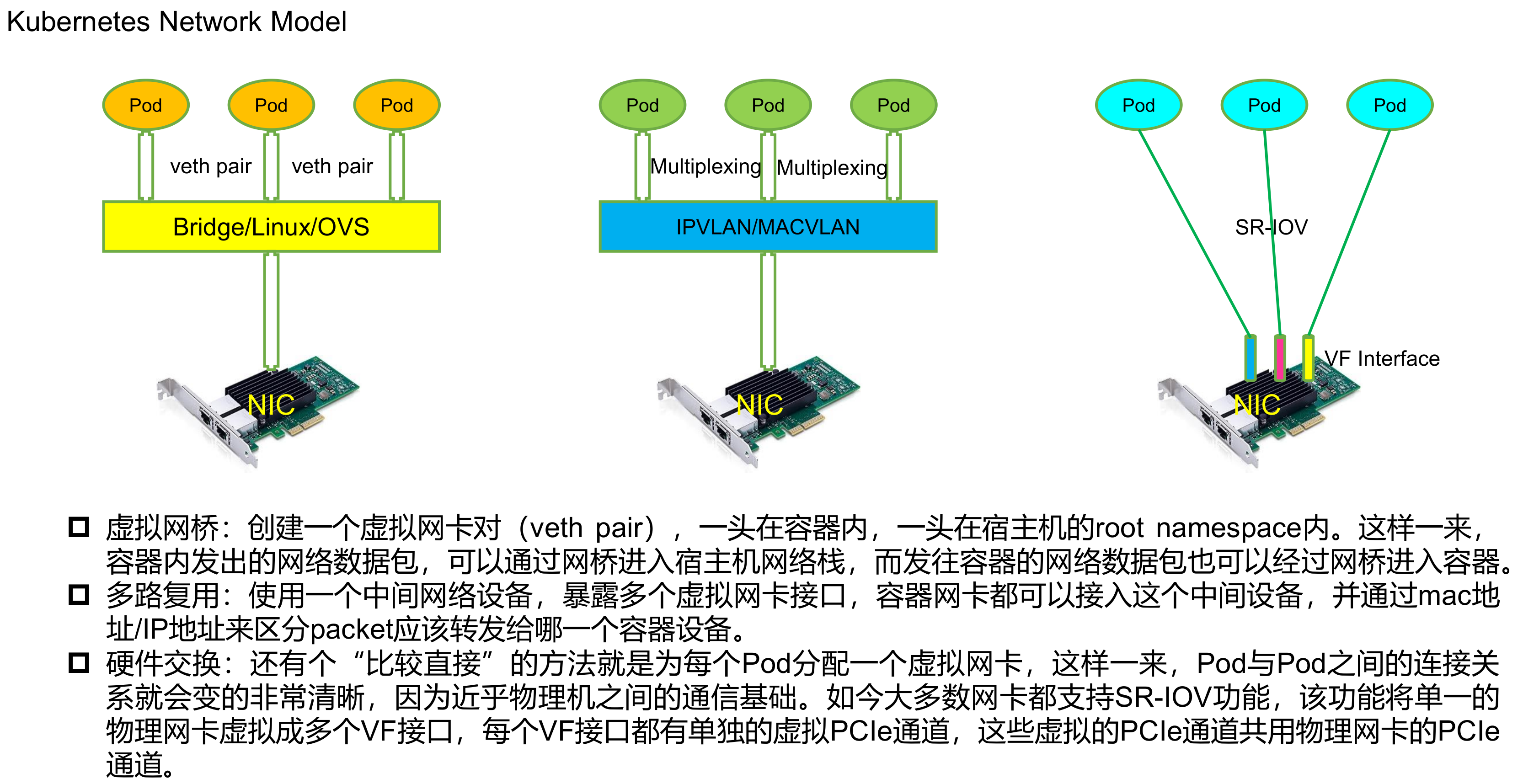
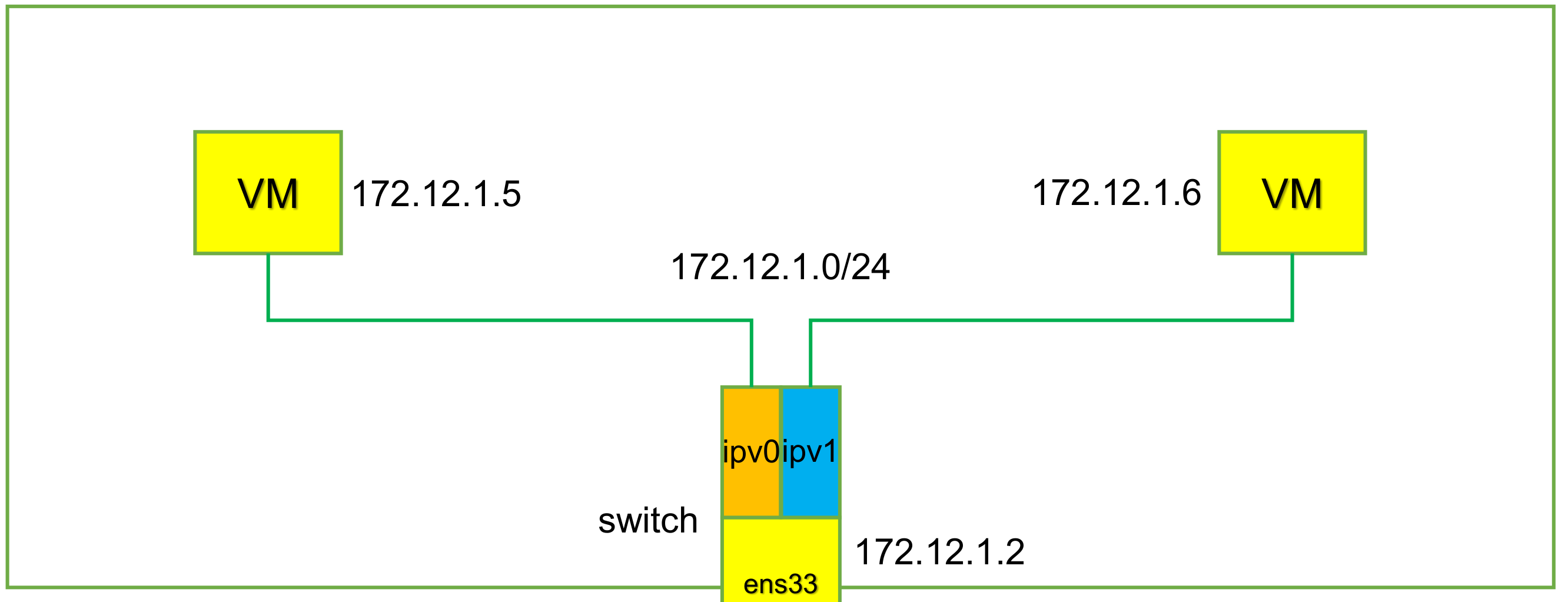
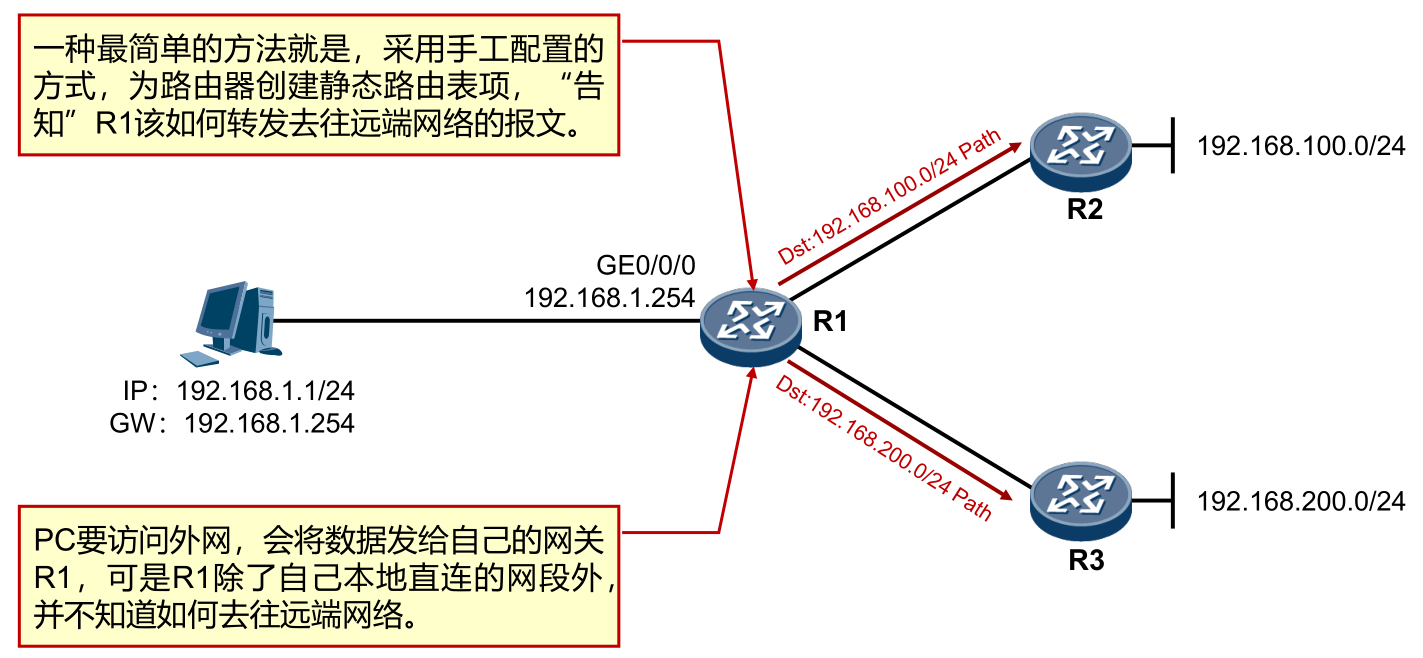
ip netns add net1 ip netns add net2 ip link add ipvlan1 link eth0 type ipvlan mode l2 ip link add ipvlan2 link eth0 type ipvlan mode l2 ip link set ipvlan1 netns net1 ip link set ipvlan2 netns net2 ip netns exec net1 ifconfig ipvlan1 172.12.1.5/24 up ip netns exec net2 ifconfig ipvlan2 172.12.1.6/24 up ##访问外网添加路由 ip netns exec net1 route add -net 0.0.0.0/0 gw 172.12.1.2 ip netns exec net2 route add -net 0.0.0.0/0 gw 172.12.1.2 $ ip netns exec net2 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.12.1.2 0.0.0.0 UG 0 0 0 ipvlan2 172.12.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ipvlan2
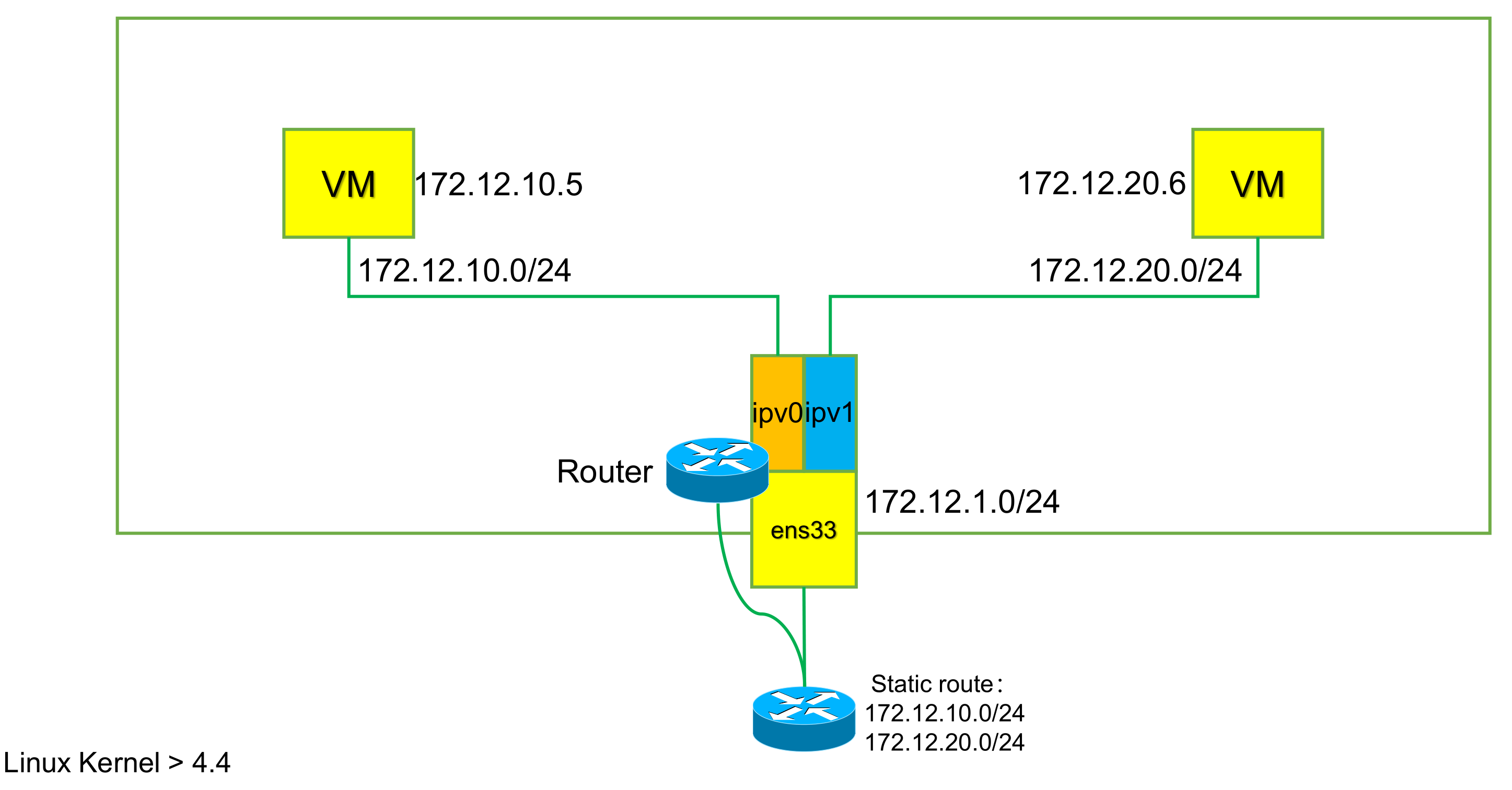
ip netns add net1 ip netns add net2 ip link add ipvlan1 link eth0 type ipvlan mode l3 ip link add ipvlan2 link eth0 type ipvlan mode l3 ip linkset ipvlan1 netns net1 ip linkset ipvlan2 netns net2 ip netns exec net1 ifconfig ipvlan1 172.12.10.5/24 up ip netns exec net2 ifconfig ipvlan2 172.12.20.6/24 up ##添加路由 ip netns exec net1 route add -net 172.12.20.0/24 dev ipvlan1 ip netns exec net2 route add -net 172.12.10.0/24 dev ipvlan2
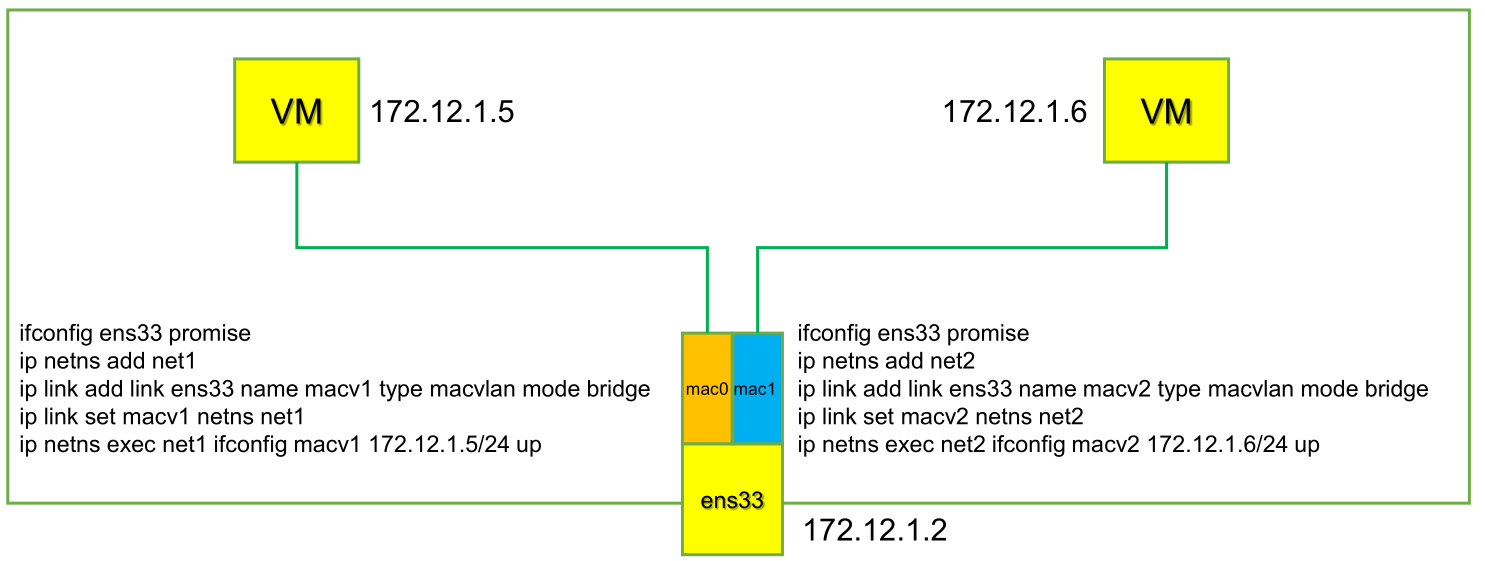
ifconfig eth0 promisc #开启混杂模式 ip netns add net1 ip netns add net2 ip link add link eth0 name macv1 type macvlan mode bridge ip link add link eth0 name macv2 type macvlan mode bridge ip link set macv1 netns net1 ip link set macv2 netns net2 ip netns exec net1 ifconfig macv1 172.12.1.5/24 up ip netns exec net2 ifconfig macv2 172.12.1.6/24 up
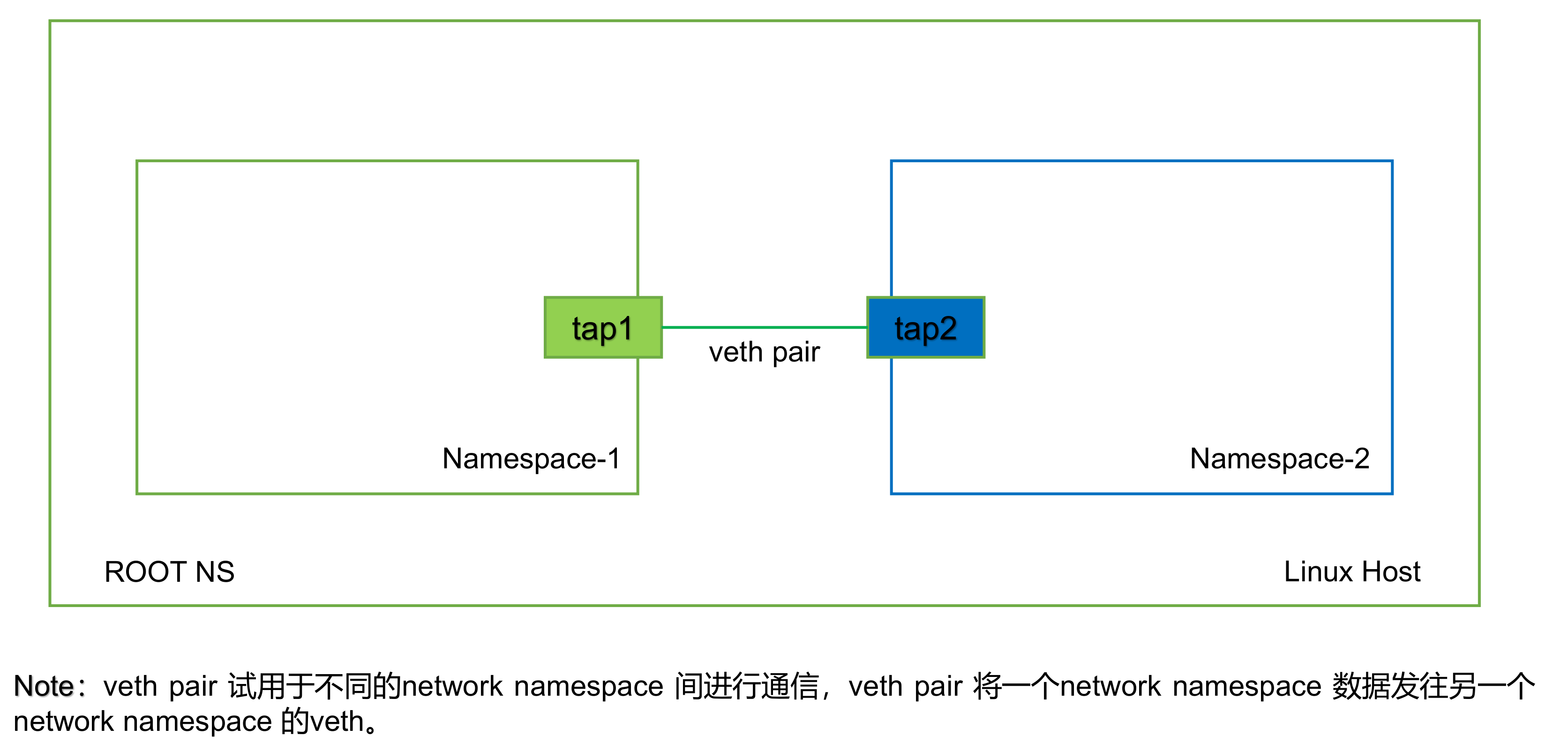
# 创建一对名为 veth0 和 veth1 的 veth 接口。 $ ip link add veth0 type veth peer name veth1
# 确认 veth0 已创建 $ ip link show veth0 289: veth0@veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 5e:87:df:87:af:c7 brd ff:ff:ff:ff:ff:ff
# 确认 veth1 已创建 $ ip link show veth1 288: veth1@veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether be:0d:a4:8c:9f:2a brd ff:ff:ff:ff:ff:ff $ip netns exec ns1 ethtool -S veth0 NIC statistics: peer_ifindex: 4 #对端id rx_queue_0_xdp_packets: 0 rx_queue_0_xdp_bytes: 0 rx_queue_0_drops: 0 rx_queue_0_xdp_redirect: 0 rx_queue_0_xdp_drops: 0 rx_queue_0_xdp_tx: 0 rx_queue_0_xdp_tx_errors: 0 tx_queue_0_xdp_xmit: 0 tx_queue_0_xdp_xmit_errors: 0 $ ip a ... 4: veth1@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 8a:5c:72:4b:c4:a3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 分配 veth1 接口到 ns2 网络命名空间 $ ip link set veth1 netns ns2
# 将 10.0.2.0/24 IP 地址范围分配给 veth1 接口 $ ip -n ns2 addr add 10.0.2.0/24 dev veth1
# 将 veth1 接口 up 起来 $ ip -n ns2 link set veth1 up
# 将 lo 口 up 起来(这样可以 ping 通自己) $ ip -n ns2 link set lo up
$ ip -n ns2 addr show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN groupdefault qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 288: veth1@if289: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP groupdefault qlen 1000 link/ether be:0d:a4:8c:9f:2a brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet10.0.2.0/24 scope global veth1 valid_lft forever preferred_lft forever inet6 fe80::bc0d:a4ff:fe8c:9f2a/64 scope link valid_lft forever preferred_lft forever
为方便后面设置路由,这里我们为 veth1 接口分配一个不同的子网 IP 范围。和 veth0 接口类似,veth1 接口也不能从主机网络命名空间到达,只能在 ns2 本身的网络命名空间内工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ ip link show veth1 Device "veth1" does not exist. $ ping -c10 10.0.2.0 PING 10.0.2.0 (10.0.2.0) 56(84) bytes of data. From 180.149.159.13 icmp_seq=2 Packet filtered ^C --- 10.0.2.0 ping statistics --- 2 packets transmitted, 0 received, +1 errors, 100% packet loss, time 999 $ ip netns exec ns2 ping -c10 10.0.2.0 PING 10.0.2.0 (10.0.2.0) 56(84) bytes of data. 64 bytes from 10.0.2.0: icmp_seq=1 ttl=64 time=0.100 ms 64 bytes from 10.0.2.0: icmp_seq=2 ttl=64 time=0.096 ms 64 bytes from 10.0.2.0: icmp_seq=3 ttl=64 time=0.068 ms ^C --- 10.0.2.0 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 0.068/0.088/0.100/0.014 ms
配置子网路由
虽然在上面的两个网络空间内可以各自访问自己,但是他们互相之间是不能 ping 通的。
1 2 3 4
$ ip netns exec ns1 ping -c10 10.0.2.0 connect: Network is unreachable $ ip netns exec ns2 ping -c10 10.0.1.0 connect: Network is unreachable
veth0 和 veth1 这两个接口本身也都 up 起来了,而且在各种的网络命名空间中 ping 也能正常工作,所以互相直接不通那很可能和路由有关。下面我们使用 ip 命令来调试下,我们可以通过 ip route get 命令来确定一个数据包所走的路由。
1 2 3 4
$ ip -n ns1 route get 10.0.2.0 RTNETLINK answers: Network is unreachable $ ip -n ns2 route get 10.0.1.0 RTNETLINK answers: Network is unreachable
我们可以看到都是网络不可达,我们来检查下两个网络命名空间中的路由表信息。
1 2 3 4
$ ip -n ns1 route 10.0.1.0/24 dev veth0 proto kernel scope link src 10.0.1.0 $ ip -n ns2 route 10.0.2.0/24 dev veth1 proto kernel scope link src 10.0.2.0
看到路由表是不是很清晰了,两个网络命名空间的路由表都只有各自 IP 范围的路由条目,并没有通往其他子网的路由,所以当然不能互通了,要解决也很简单,可以使用 ip route add 命令在路由表中插入新的路由条目是不是就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 更新 veth0 路由表,添加一条通往 10.0.2.0/24 的路由 $ ip -n ns1 route add 10.0.2.0/24 dev veth0
# 确认发往 10.0.2.0/24 的数据包被路由到 veth0 $ ip -n ns1 route get 10.0.2.0 10.0.2.0 dev veth0 src 10.0.1.0 cache
# 同样更新 veth1 路由表,添加一条通往 10.0.1.0/24 的路由 $ ip -n ns2 route add 10.0.1.0/24 dev veth1
# 确认发往 10.0.1.0/24 的数据包被路由到 veth1 $ ip -n ns2 route get 10.0.1.0 10.0.1.0 dev veth1 src 10.0.2.0 cache
$ ip netns exec ns1 nc -l 10.0.1.07096 -v exec of "nc" failed: No such file or directory
上面命令报错是因为我们还没有安装 ns 这个工具,安装完成后就正常了。
1 2 3 4 5
$ yum install -y nc
$ ip netns exec ns1 nc -l 10.0.1.07096 -v Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Listening on 10.0.1.0:7096
然后重新开一个终端进行连接:
1 2 3 4 5 6 7 8 9 10 11
# 使用 nc 从 ns2 发起 TCP 握手 $ ip netns exec ns2 nc -4t 10.0.1.07096 -v Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Connected to 10.0.1.0:7096.
# 这个时候正常会在前面的服务中看到连接状态 $ ip netns exec ns1 nc -l 10.0.1.07096 -v Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Listening on 10.0.1.0:7096 Ncat: Connection from 10.0.2.0. Ncat: Connection from 10.0.2.0:34090.
一旦 TCP 连接建立,我们就可以从 ns2 向 ns1 发送测试消息了。
1 2 3 4
$ ip netns exec ns2 nc -4t 10.0.1.07096 -v Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Connected to 10.0.1.0:7096. this is a test message # 在这里输入一段信息
此时我们在 ns1 这边的服务器端也会收到发送的消息。
1 2 3 4 5 6
$ ip netns exec ns1 nc -l 10.0.1.07096 -v Ncat: Version7.50 ( https://nmap.org/ncat ) Ncat: Listening on10.0.1.0:7096 Ncat: Connectionfrom10.0.2.0. Ncat: Connectionfrom10.0.2.0:34090. this is a test message
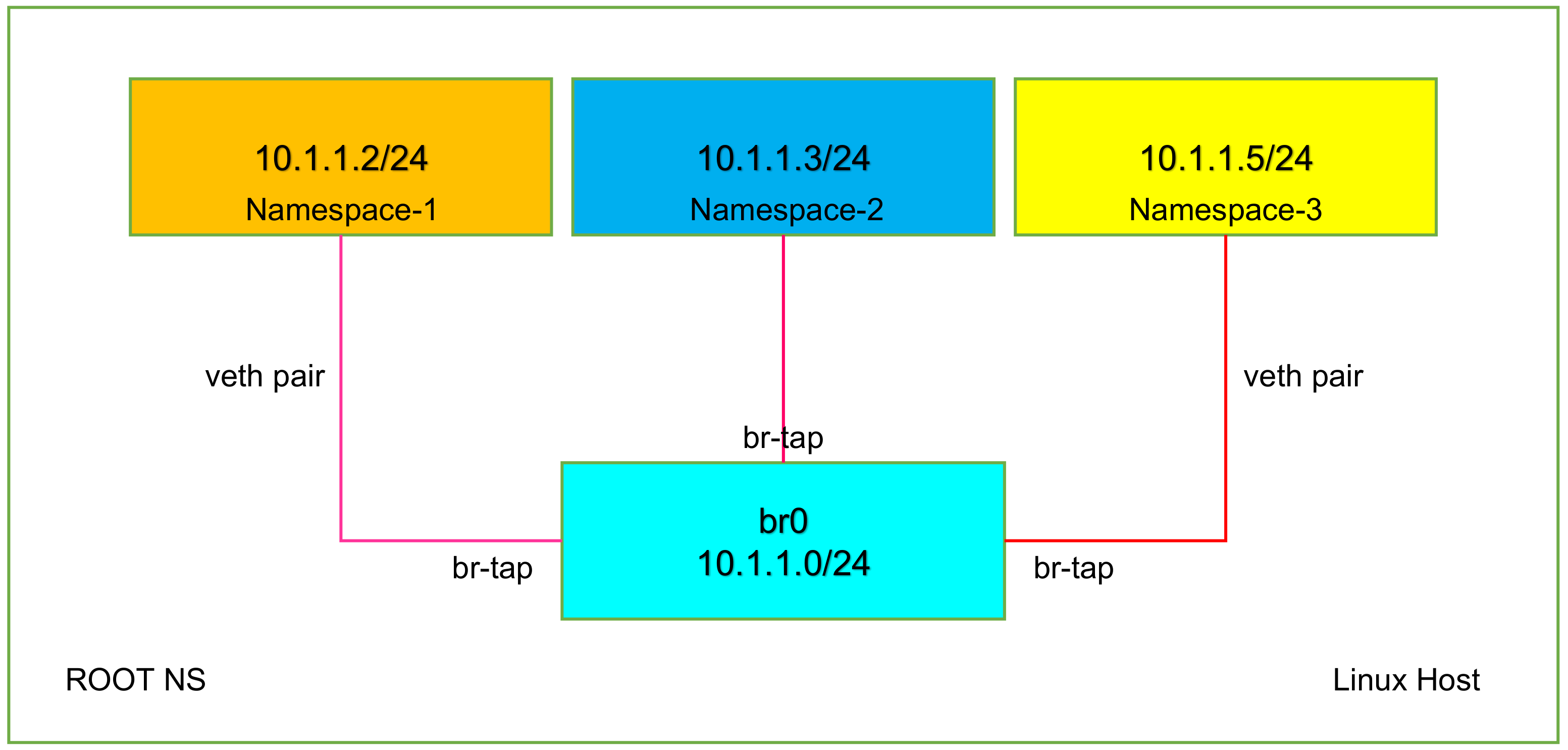
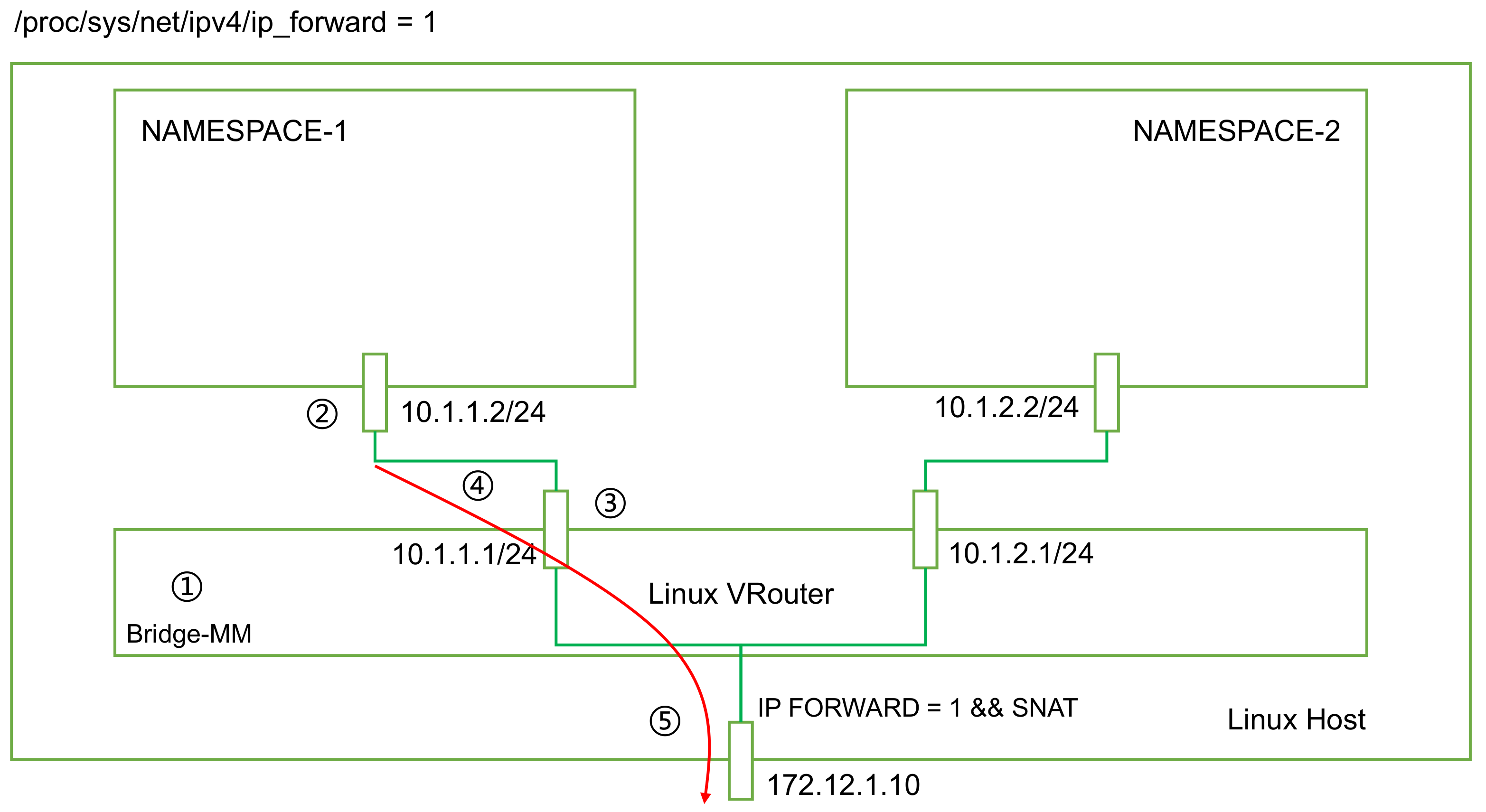
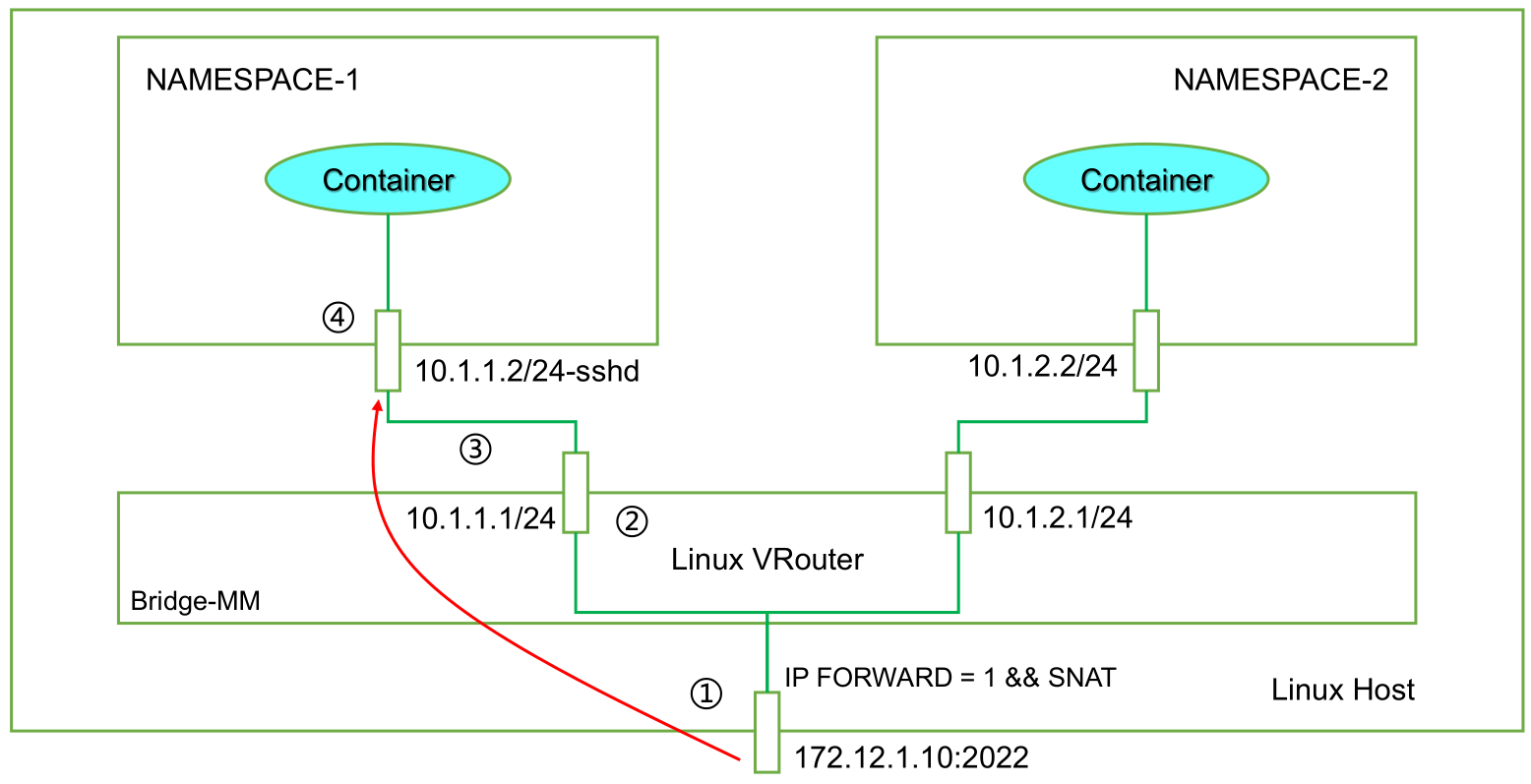
#创建命名空间 ip netns add ns1 ip netns add ns2 #首先创建 bridge br0 ip l a br0 type bridge ip l s br0 up #然后创建两对 veth-pair ip l a veth0 type veth peer name br-veth0 ip l a veth1 type veth peer name br-veth1 #分别将两对 veth-pair 加入两个 ns 和 br0 ip l s veth0 netns ns1 ip l s br-veth0 master br0 ip l s br-veth0 up ip l s veth1 netns ns2 ip l s br-veth1 master br0 ip l s br-veth1 up #开启本地回环 ip netns exec ns1 ip l s lo up ip netns exec ns2 ip l s lo up #给两个 ns 中的 veth 配置 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up
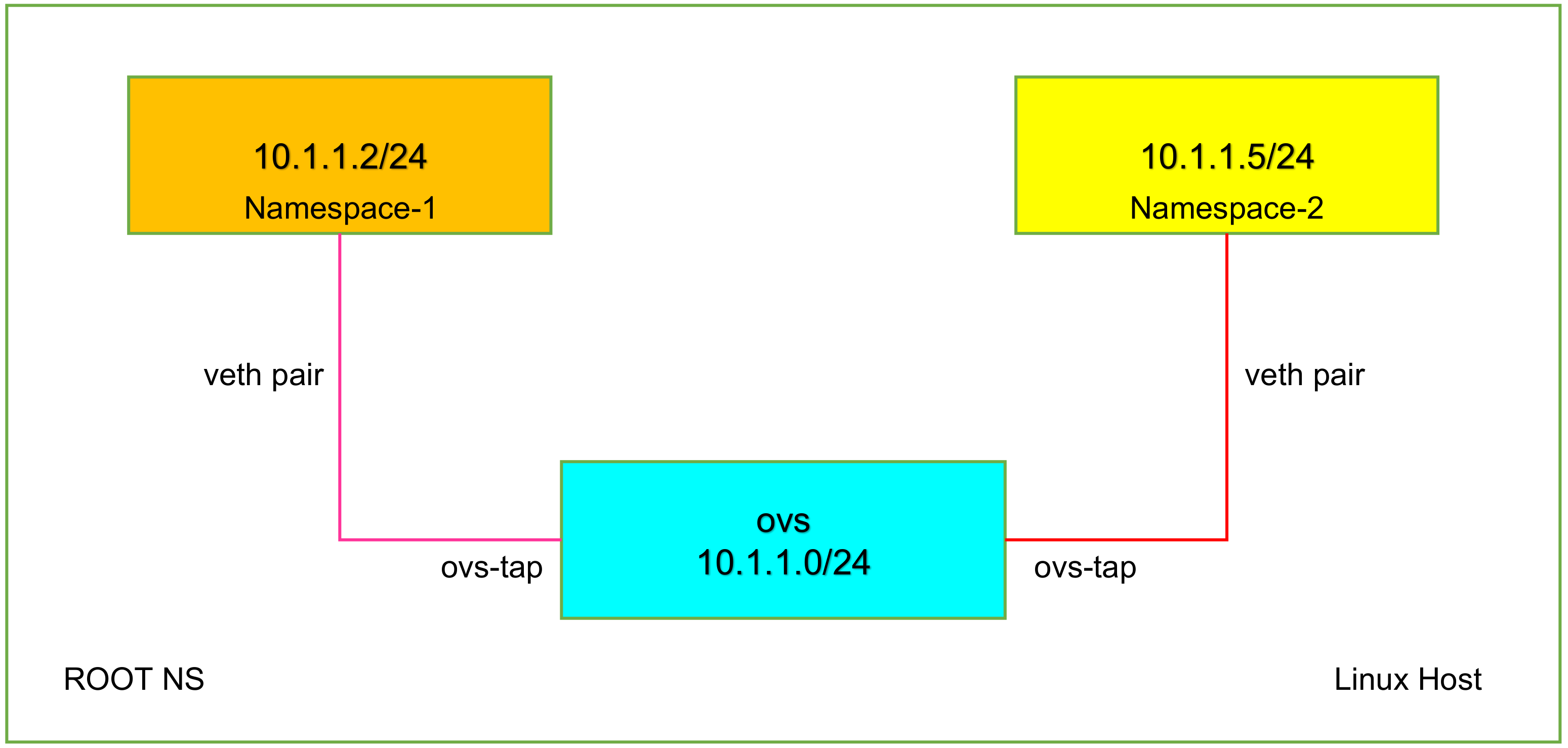
#用 ovs 提供的命令创建一个 ovs bridge ovs-vsctl add-br ovs-br ovs-vsctl show 2349b536-c235-4e10-8c81-804bded82184 Bridge pvs-br Port pvs-br Interface ovs-br type: internal ovs_version: "2.5.2" #创建两对 veth-pair ip l a veth0 type veth peer name ovs-veth0 ip l a veth1 type veth peer name ovs-veth1 #将 veth-pair 两端分别加入到 ns 和 ovs bridge 中 ip l s veth0 netns ns1 ovs-vsctl add-port ovs-br ovs-veth0 ip l s ovs-veth0 up ip l s veth1 netns ns2 ovs-vsctl add-port ovs-br ovs-veth1 ip l s ovs-veth1 up #给 ns 中的 veth 配置 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up
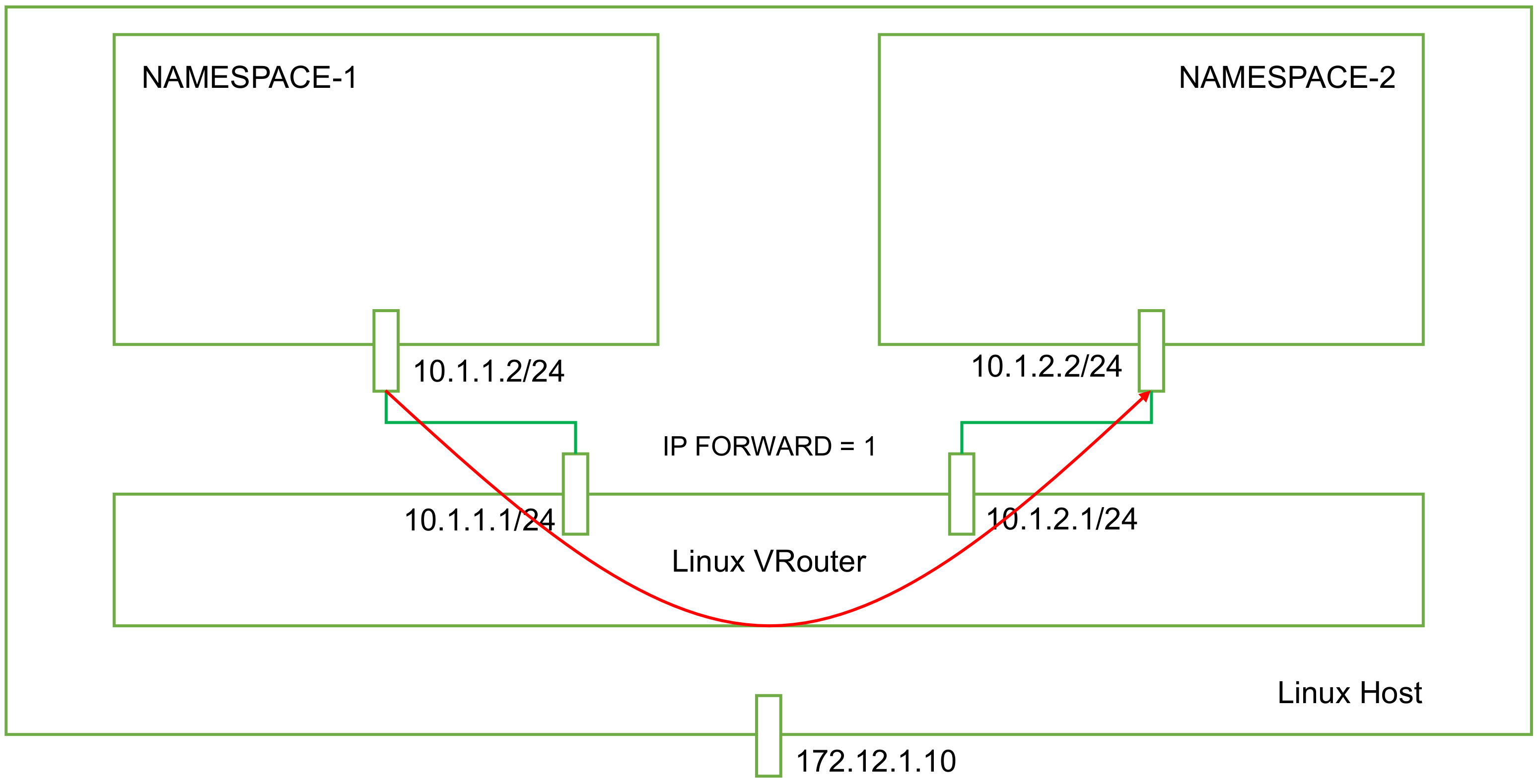
#创建两个 namespace: ip netns add ns1 ip netns add ns2 #创建两对 veth-pair,一端分别挂在两个 namespace 中: ip link add v1 type veth peer name v1_r ip link add v2 type veth peer name v2_r ip linkset v1 netns ns1 ip linkset v2 netns ns2 #分别给两对 veth-pair 端点配上 IP 并启用: ip a a 10.1.1.1/24 dev v1_r ip l s v1_r up ip a a 10.1.2.1/24 dev v2_r ip l s v2_r up ip netns exec ns1 ip a a 10.1.1.2/24 dev v1 ip netns exec ns1 ip l s v1 up ip netns exec ns2 ip a a 10.1.2.2/24 dev v2 ip netns exec ns2 ip l s v2 up #添加路由: ip netns exec ns1 route add -net 10.1.2.0 netmask 255.255.255.0 gw 10.1.1.1 ip netns exec ns2 route add -net 10.1.1.0 netmask 255.255.255.0 gw 10.1.2.1 #修改内核转发: echo 1 > /proc/sys/net/ipv4/ip_forward
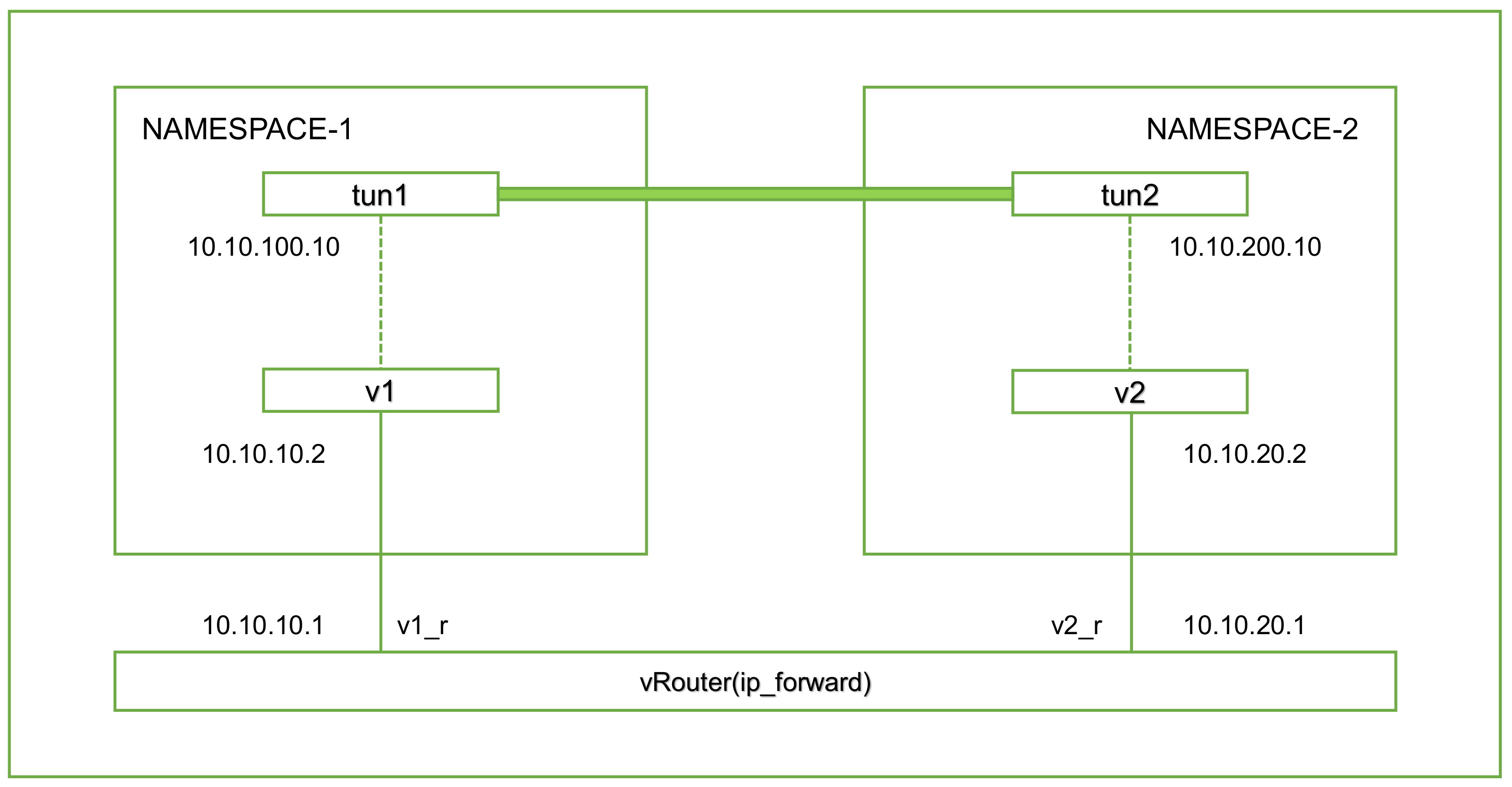
# 创建ns ip netns add ns1 ip netns add ns2 # 添加虚拟网卡对 ip link add v1 type veth peer name v1_r ip link add v2 type veth peer name v2_r ip linkset v1 netns ns1 ip linkset v2 netns ns2 # 添加地址 ip a a 10.10.10.1/24 dev v1_r ip l s v1_r up ip a a 10.10.20.1/24 dev v2_r ip l s v2_r up ip netns exec ns1 ip a a 10.10.10.2/24 dev v1 ip netns exec ns1 ip l s v1 up ip netns exec ns2 ip a a 10.10.20.2/24 dev v2 ip netns exec ns2 ip l s v2 up # 添加路由 ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1 ip netns exec ns2 route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.20.1 # 添加ip转发 echo 1 > /proc/sys/net/ipv4/ip_forward Kubernetes Network IPIP Mode # 在 ns1 上创建 tun1 和 IPIP tunnel ip netns exec ns1 ip tunnel add tun1 mode ipip remote 10.10.20.2 local 10.10.10.2 ip netns exec ns1 ip l s tun1 up ip netns exec ns1 ip a a 10.10.100.10 peer 10.10.200.10 dev tun1 # 在 ns2 上创建 tun1 和 IPIP tunnel ip netns exec ns2 ip tunnel add tun2 mode ipip remote 10.10.10.2 local 10.10.20.2 ip netns exec ns2 ip l s tun2 up ip netns exec ns2 ip a a 10.10.200.10 peer 10.10.100.10 dev tun2 # 上面的命令是在 NS1 上创建 tun 设备 tun1,并设置隧道模式为 ipip,然后还需要设置道端点,用 remote 和 local表示,这是 隧道外层 IP,对应的还有 隧道内层 IP,用 ip addr xx peer xx 配置。 ip netns exec ns1 ping 10.10.200.10 -c 4 PING 10.10.200.10 (10.10.200.10) 56(84) bytes of data. 64 bytes from 10.10.200.10: icmp_seq=1 ttl=64 time=0.090 ms 64 bytes from 10.10.200.10: icmp_seq=2 ttl=64 time=0.148 ms 64 bytes from 10.10.200.10: icmp_seq=3 ttl=64 time=0.112 ms 64 bytes from 10.10.200.10: icmp_seq=4 ttl=64 time=0.110 ms --- 10.10.200.10 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3000ms rtt min/avg/max/mdev = 0.090/0.115/0.148/0.020 ms
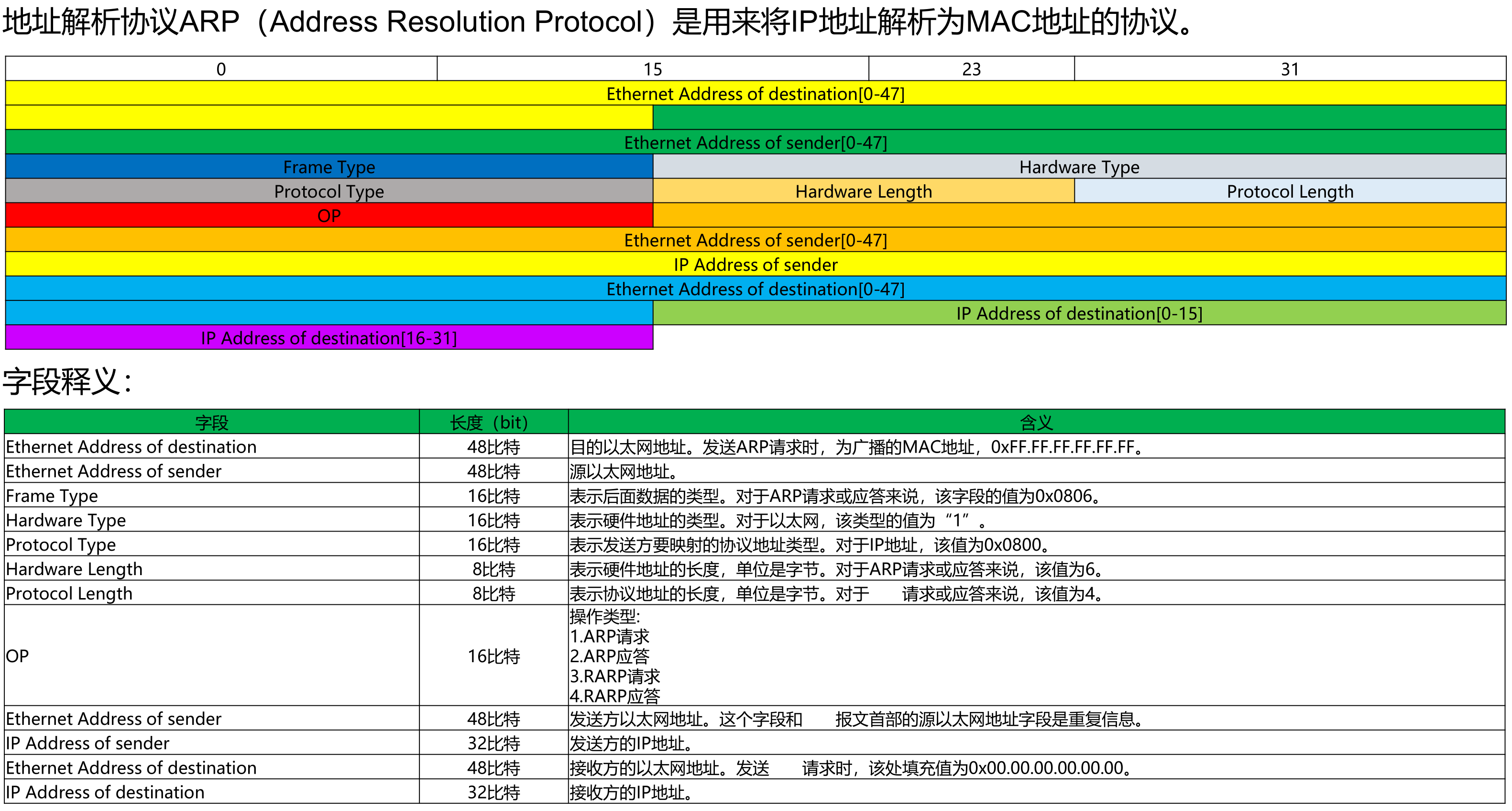
ARP 与 PROXY ARP
ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标IP对应的MAC地址。
#node1 ip link add veth1 type veth peer name eth1 ip netns add ns0 ip linkset eth1 netns ns0 ip netns exec ns0 ip a add 10.1.1.10/24 dev eth1 ip netns exec ns0 ip linkset eth1 up ip netns exec ns0 ip route add 169.254.1.1 dev eth1 scope link ip netns exec ns0 ip route add default via 169.254.1.1 dev eth1 ip linkset veth1 up ip route add 10.1.1.10 dev veth1 scope link ip route add 10.1.1.20 via 172.12.1.11 dev eth0 echo 1 > /proc/sys/net/ipv4/conf/veth0/proxy_arp #node2 ip link add veth1 type veth peer name eth1 ip netns add ns0 ip linkset eth1 netns ns0 ip netns exec ns0 ip a add 10.1.1.20/24 dev eth1 ip netns exec ns0 ip linkset eth1 up ip netns exec ns0 ip route add 169.254.1.1 dev eth1 scope link ip netns exec ns0 ip route add default via 169.254.1.1 dev eth1 ip linkset veth1 up ip route add 10.1.1.20 dev veth1 scope link ip route add 10.1.1.10 via 172.12.1.10 dev eth0 echo 1 > /proc/sys/net/ipv4/conf/veth0/proxy_arp
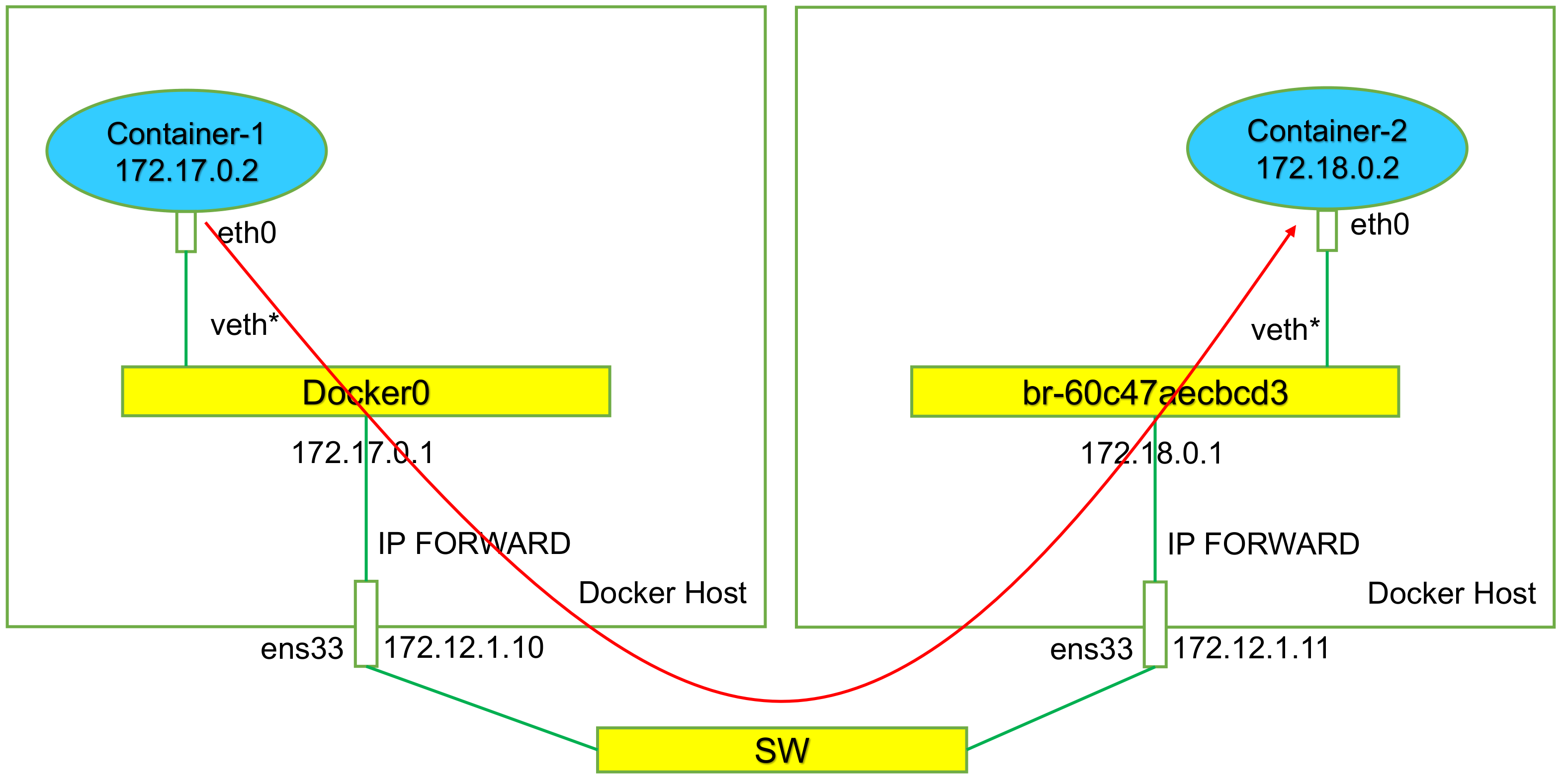
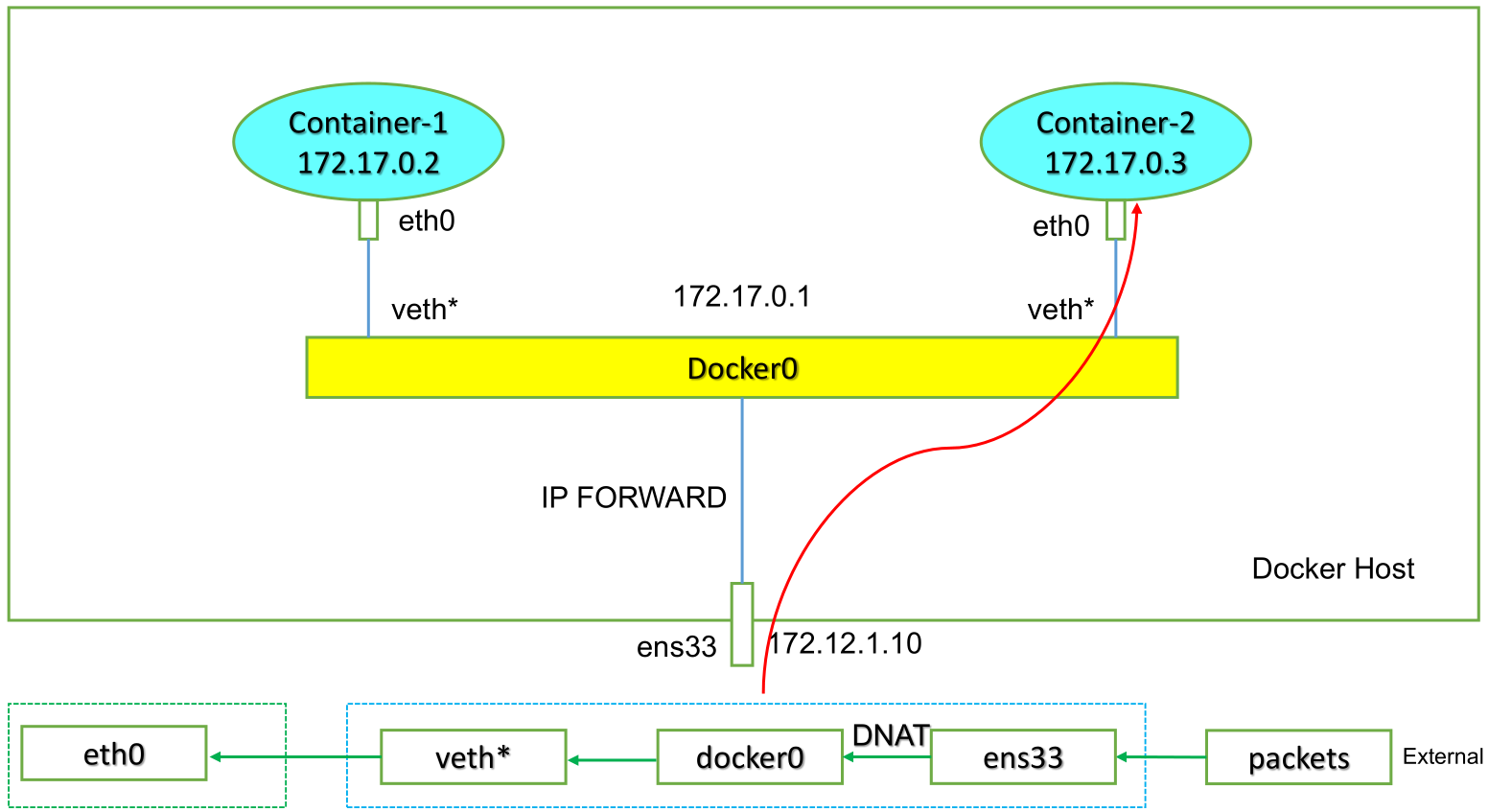
#添加br0: ip netns add ns1 ip l a br0 type bridge ip l s br0 up #配置br0和veth: ip l a veth0 type veth peer name br-veth0 ip l s veth0 netns ns1 ip l s br-veth0 master br0 ip l s br-veth0 up #配置ns1中接口: ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip a a 10.1.1.1/24 dev br0 ip l s br0 up ip netns exec ns1 ifconfig lo up #添加路由: ip netns exec ns1 route add -net 0.0.0.0 netmask 0.0.0.0 gw 10.1.1.1 #修改内核转发: echo 1 > /proc/sys/net/ipv4/ip_forward #添加SNAT规则: iptables -t nat -A POSTROUTING -s 10.1.1.0/24 ! -o br0 -j MASQUERADE
[AR1] <Huawei>sys [Huawei]sysname AR1 [AR1]int g0/0/0 [AR1-GigabitEthernet0/0/0]ip a 192.168.12.124 [AR1-GigabitEthernet0/0/0]q <AR1>dis int brief [AR1]dis ip int b [AR1]dis this [AR1]ip route-static192.168.23.024192.168.12.2
1 2 3 4
[AR2] [AR2-GigabitEthernet0/0/0]ip a192.168.12.224 [AR2-GigabitEthernet0/0/1]ip a192.168.23.124 [AR2-GigabitEthernet0/0/1]display ip routing-table
1 2 3
[AR3] [AR3-GigabitEthernet0/0/0]ip a 192.168.23.224 [AR3-GigabitEthernet0/0/0]ip route-static192.168.12.024192.168.23.1
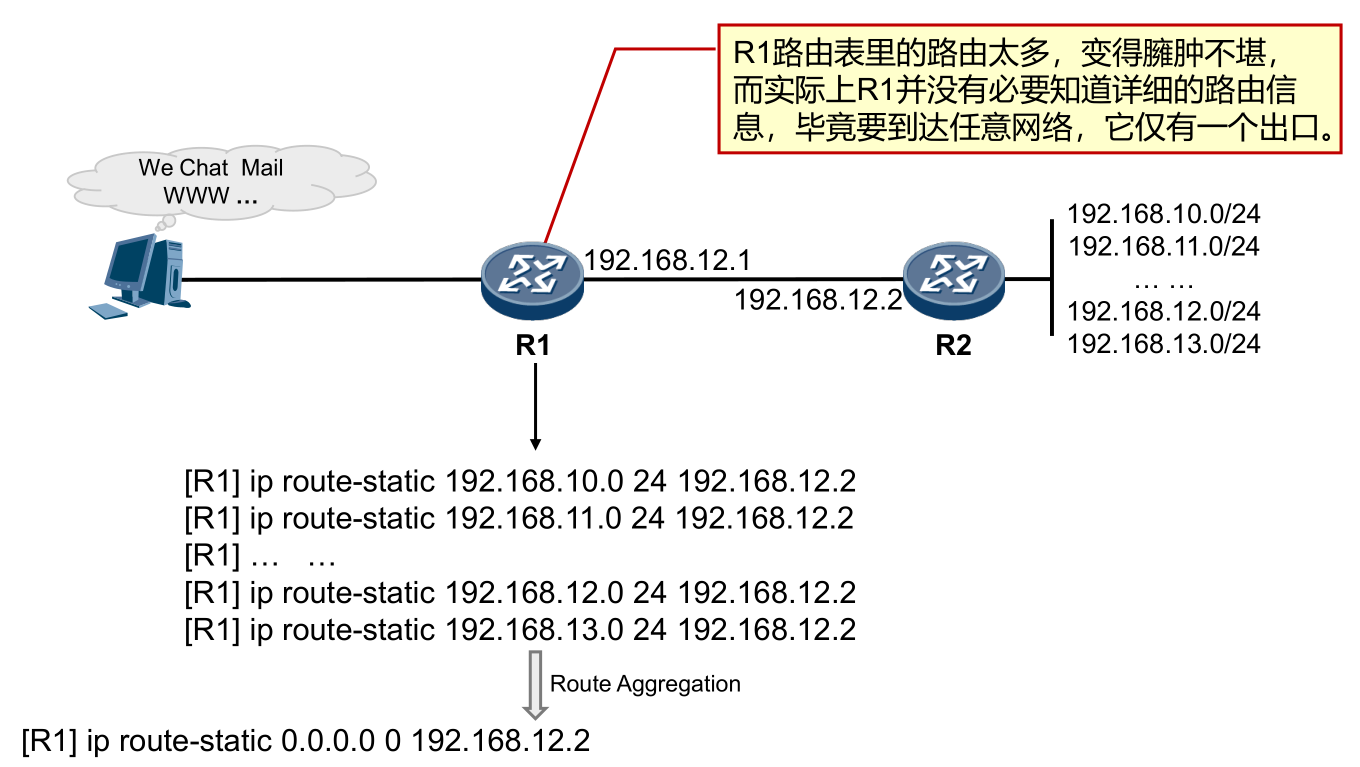
Static Route - Default Route
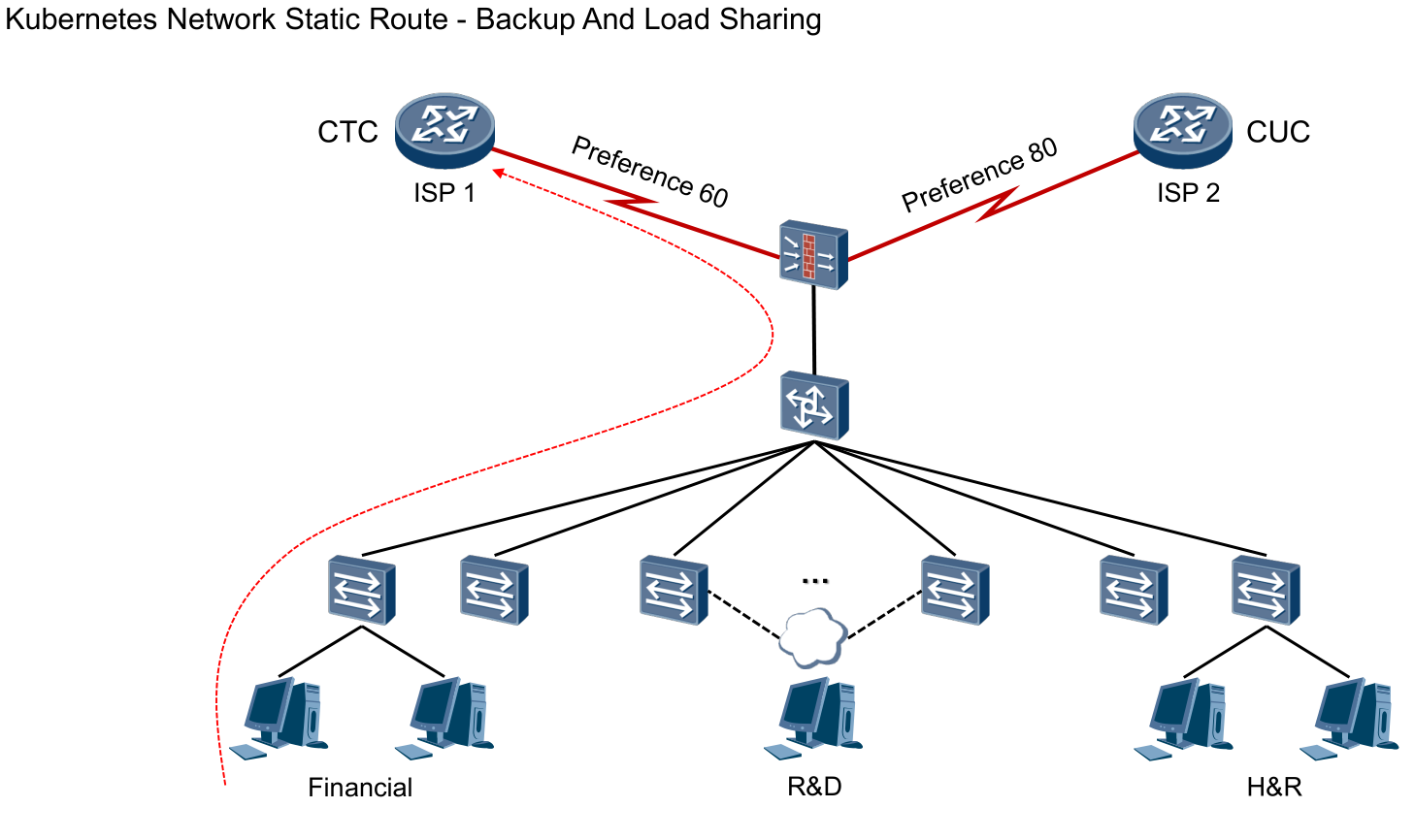
多出口
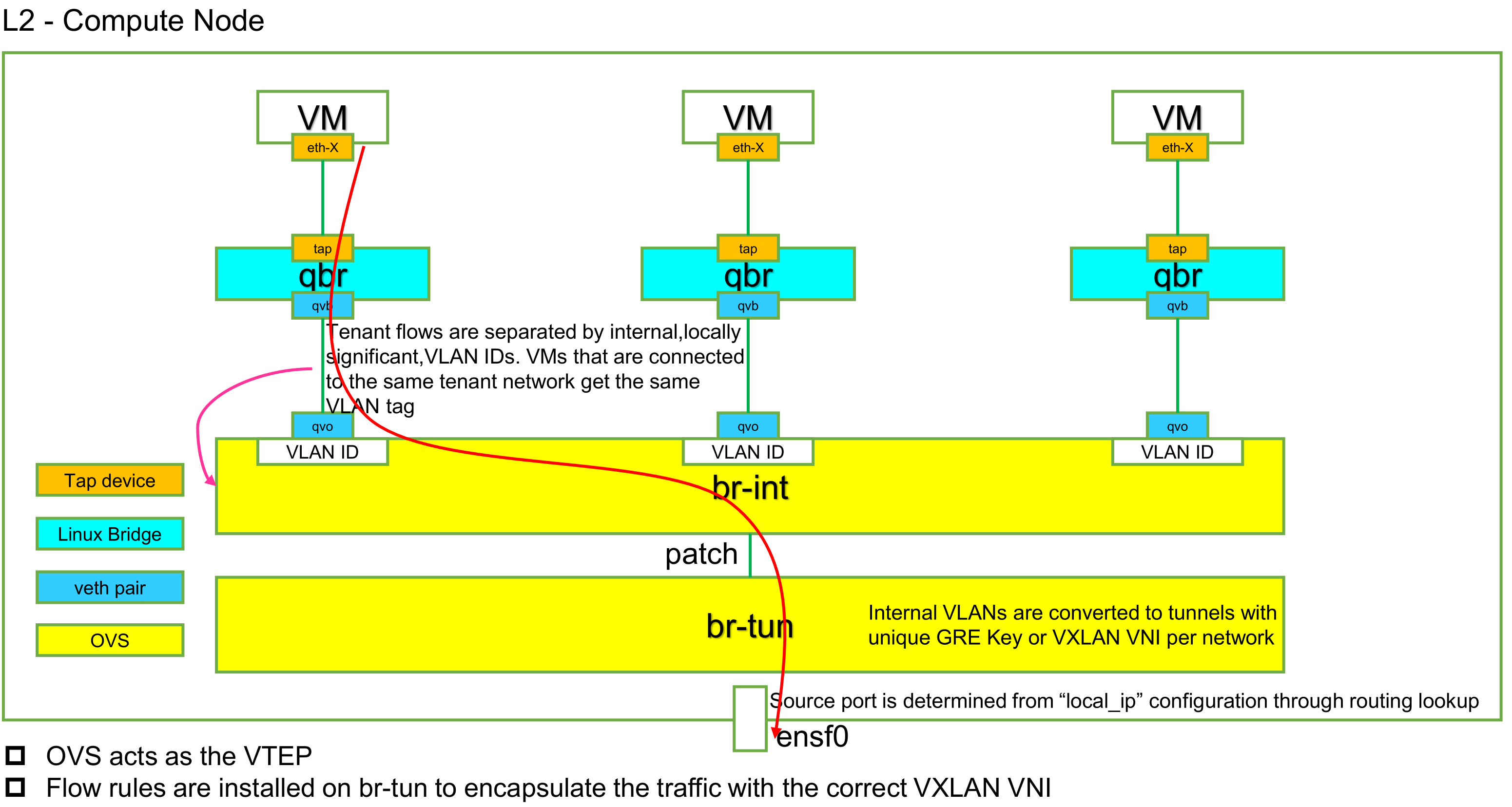
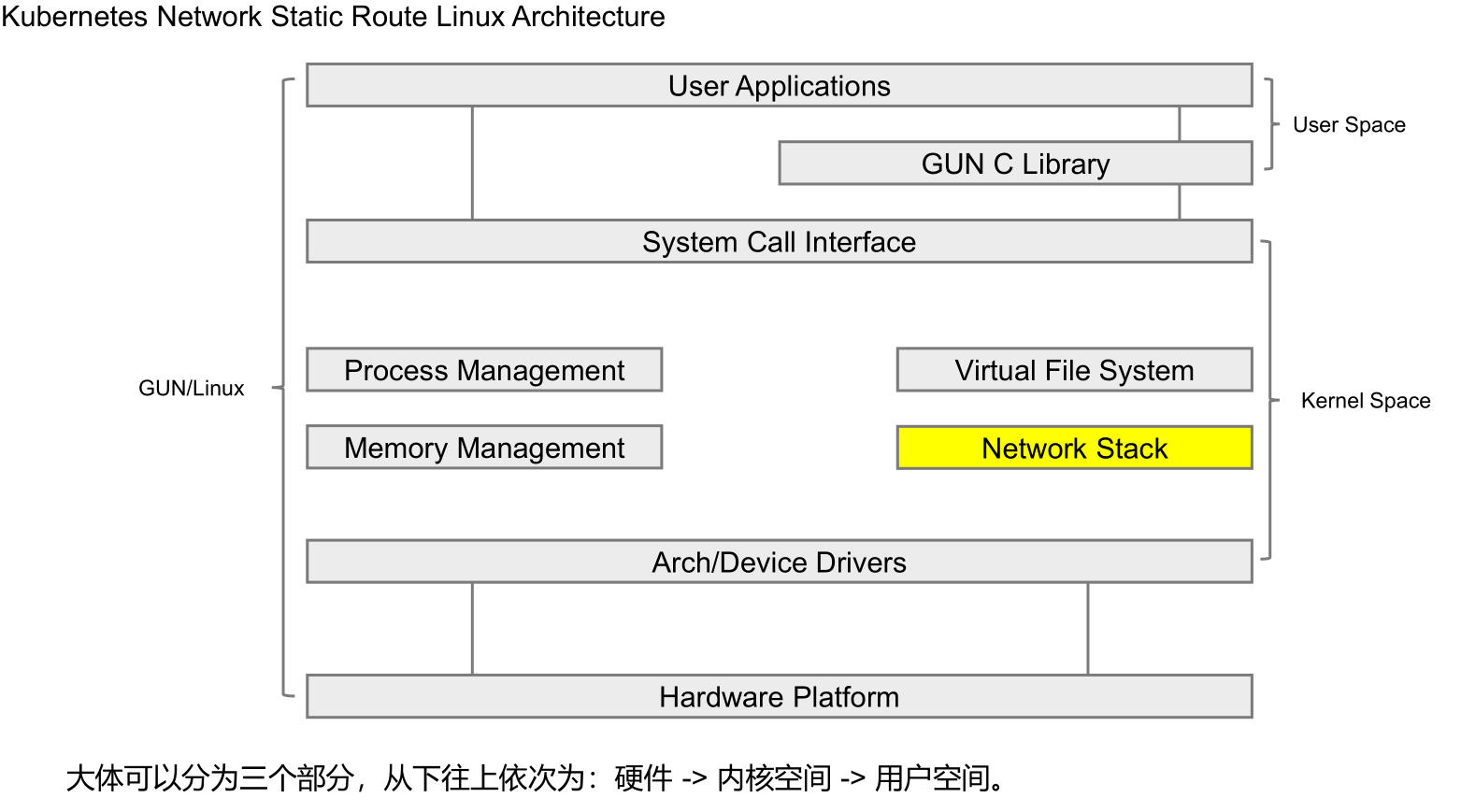
Linux Architecture
Linux Static Route
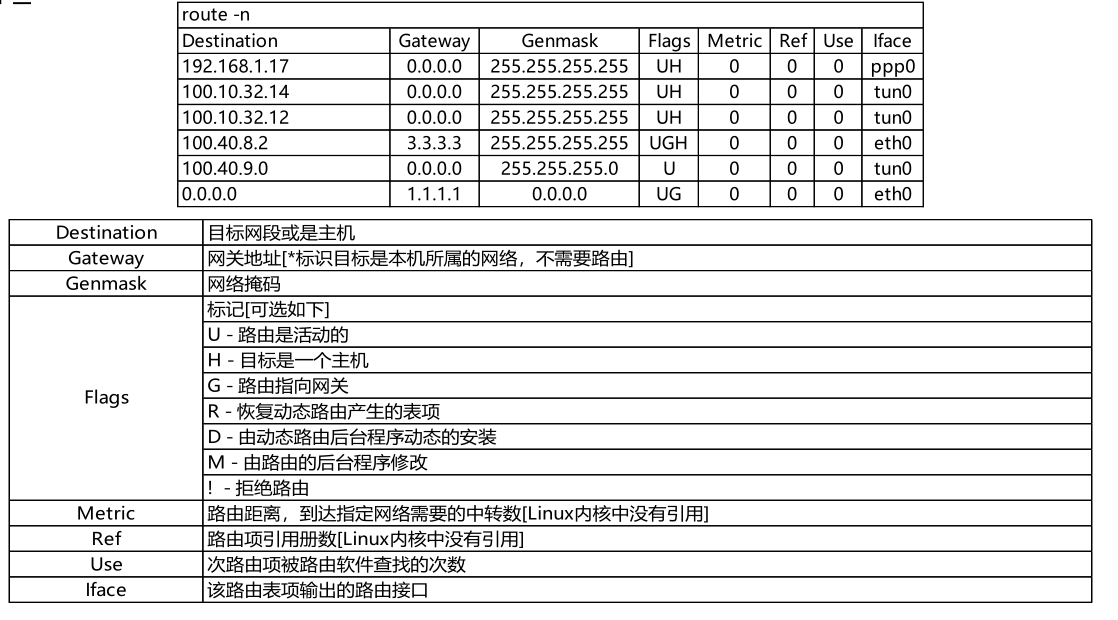
Linux系统的route命令用于显示和操作IP路由表(show/manipulate the IP routing table)。
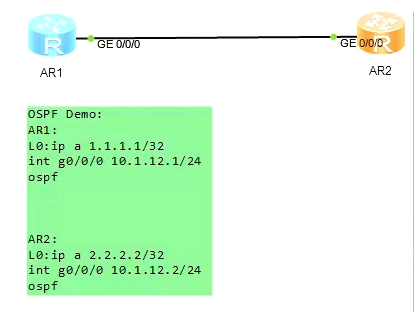
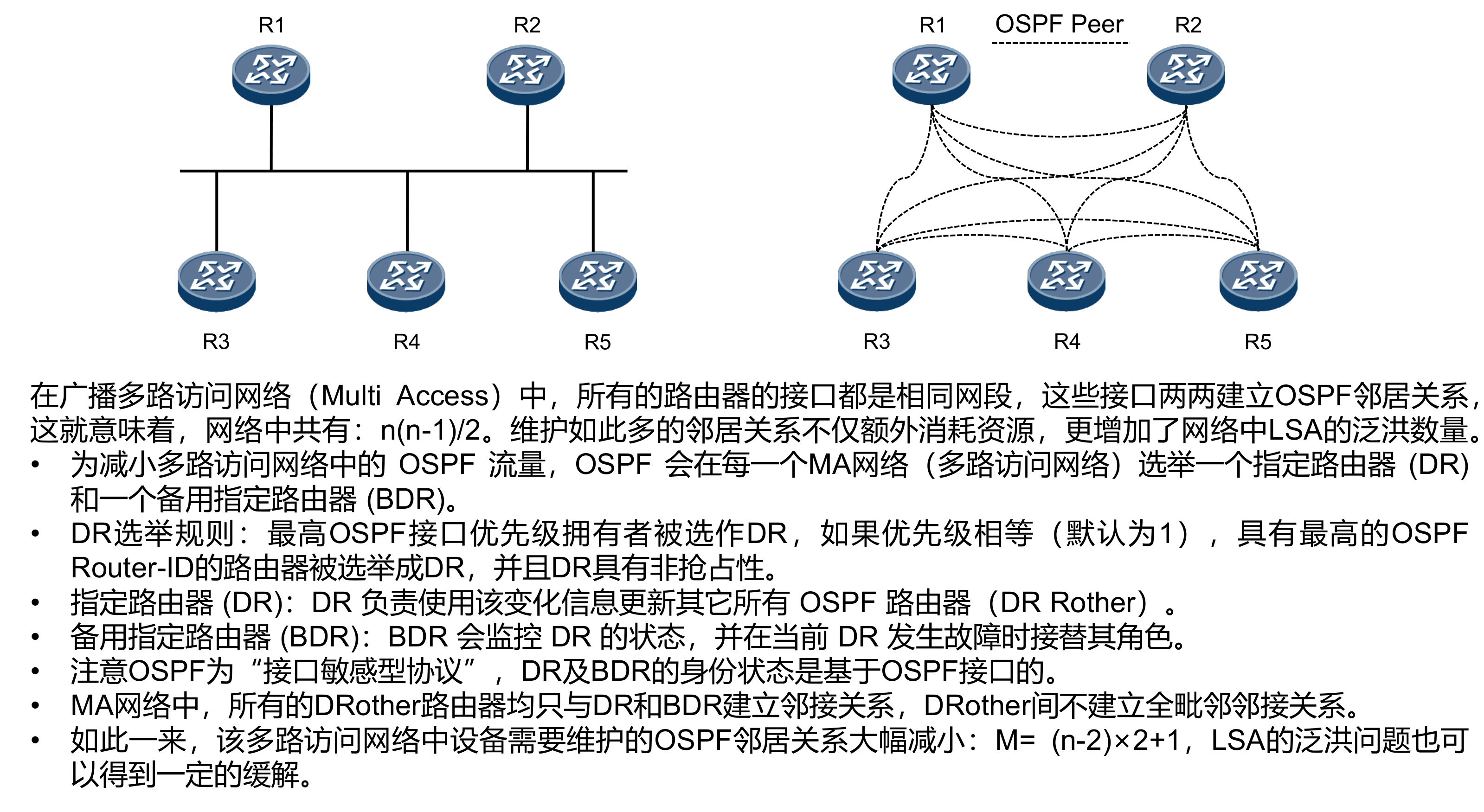
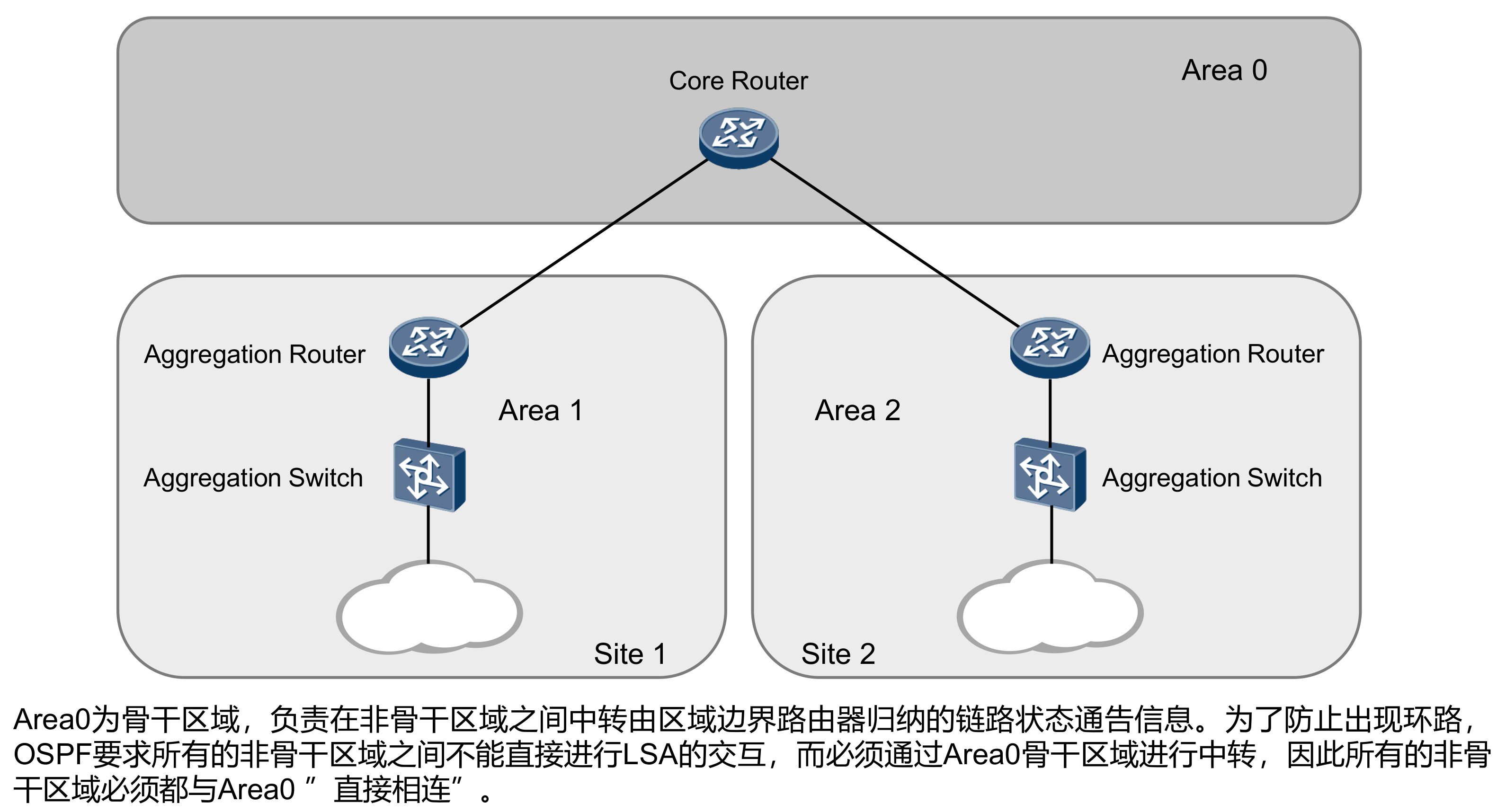
开放式最短路径优先OSPF(Open Shortest Path First)是IETF组织开发的一个基于链路状态的内部网关协议。目前针对IPv4协议使用的是OSPF Version 2(RFC2328);针对IPv6协议使用OSPF Version 3(RFC2740)。如无特殊说明,本文中所指的OSPF均为OSPF Version 2。
<Huawei>sys Enter system view, return user view with Ctrl+Z. [Huawei]sysname AR1 [AR1]int lo0 [AR1-LoopBack0]ip a 1.1.1.1 32 [AR1-LoopBack0]dis this [V200R003C00] # interface LoopBack0 ip address 1.1.1.1 255.255.255.255 # return [AR1-LoopBack0]q [AR1]int g0/0/0 [AR1-GigabitEthernet0/0/0]ip a 10.1.12.1 24 Dec 15 2020 15:15:57-08:00 AR1 %%01IFNET/4/LINK_STATE(l)[1]:The line protocol IP on the interface GigabitEthernet0/0/0 has entered the UP state. [AR1-GigabitEthernet0/0/0]dis this [V200R003C00] # interface GigabitEthernet0/0/0 ip address 10.1.12.1 255.255.255.0 # return [AR1-GigabitEthernet0/0/0]
[AR1]ospf router-id 1.1.1.1 [AR1-ospf-1]area 0 [AR1-ospf-1-area-0.0.0.0]network 1.1.1.1 0.0.0.0 #宣告网络 [AR1-ospf-1-area-0.0.0.0]dis ip routing-table Route Flags: R - relay, D - download to fib ------------------------------------------------------------------------------ Routing Tables: Public Destinations : 8 Routes : 8
Destination/Mask Proto Pre Cost Flags NextHop Interface
1.1.1.1/32 Direct 0 0 D 127.0.0.1 LoopBack0 10.1.12.0/24 Direct 0 0 D 10.1.12.1 GigabitEthernet 0/0/0 10.1.12.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet 0/0/0 10.1.12.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet 0/0/0 127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0 127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0 127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 [AR1-ospf-1-area-0.0.0.0]network 10.1.12.0 0.0.0.255 [AR1-ospf-1-area-0.0.0.0]dis this [V200R003C00] # area 0.0.0.0 network 1.1.1.1 0.0.0.0 network 10.1.12.0 0.0.0.255 # return [AR2-ospf-1-area-0.0.0.0]display ospf peer b
OSPF Process 1 with Router ID 2.2.2.2 Peer Statistic Information ---------------------------------------------------------------------------- Area Id Interface Neighbor id State 0.0.0.0 GigabitEthernet0/0/0 1.1.1.1 Full ---------------------------------------------------------------------------- [AR1]display ospf routing
OSPF Process 1 with Router ID 1.1.1.1 Routing Tables
Routing for Network Destination Cost Type NextHop AdvRouter Area 1.1.1.1/32 0 Stub 1.1.1.1 1.1.1.1 0.0.0.0 10.1.12.0/24 1 Transit 10.1.12.1 1.1.1.1 0.0.0.0 2.2.2.2/32 1 Stub 10.1.12.2 2.2.2.2 0.0.0.0
Total Nets: 3 Intra Area: 3 Inter Area: 0 ASE: 0 NSSA: 0
<Huawei>sys Enter system view, return user view with Ctrl+Z. [Huawei]sysna [Huawei]sysname AR2 [AR2]int lo0 [AR2-LoopBack0]ip a 2.2.2.232 [AR2-LoopBack0]dis this [V200R003C00] # interface LoopBack0 ip address 2.2.2.2255.255.255.255 # return [AR2-LoopBack0]int g0/0/0 [AR2-GigabitEthernet0/0/0]ip a 10.1.12.224 Dec 15202015:18:32-08:00 AR2 %%01IFNET/4/LINK_STATE(l)[0]:The line protocol IP on the interface GigabitEthernet0/0/0 has entered the UP state. [AR2-GigabitEthernet0/0/0]dis this [V200R003C00] # interface GigabitEthernet0/0/0 ip address 10.1.12.2255.255.255.0 # return
#AR1 [Huawei]sysname AR1 [AR1]int GigabitEthernet 0/0/0 [AR1-GigabitEthernet0/0/0]ip a 10.1.12.1 24 [AR1-GigabitEthernet0/0/0]dis this ip address 10.1.12.1 255.255.255.0
[AR1-GigabitEthernet0/0/0]int l 0 [AR1-LoopBack0]ip a 1.1.1.1 32 [AR1-LoopBack0]dis this ip address 1.1.1.1 255.255.255.255
1 2 3 4 5 6 7
#AR2 [AR2]int g0/0/0 [AR2-GigabitEthernet0/0/0]ip a 10.1.12.2 24 [AR2-GigabitEthernet0/0/0]int g0/0/1 [AR2-GigabitEthernet0/0/1]ip a 10.1.23.2 24 [AR2-GigabitEthernet0/0/1]int l 0 [AR2-LoopBack0]ip a 2.2.2.2 32
1 2 3 4 5
#AR3 [AR3]int g0/0/0 [AR3-GigabitEthernet0/0/0]ip a 10.1.23.3 24 [AR3-GigabitEthernet0/0/0]int l 0 [AR3-LoopBack0]ip a 3.3.3.3 32
OSPF Process 1 with Router ID 1.1.1.1 Peer Statistic Information ---------------------------------------------------------------------------- Area Id Interface Neighbor id State 0.0.0.0 GigabitEthernet0/0/0 2.2.2.2 Full ----------------------------------------------------------------------------
检查
1 2 3 4 5 6 7 8
[AR1-ospf-1-area-0.0.0.0]dis ospf peer b
OSPF Process 1 with Router ID 1.1.1.1 Peer Statistic Information ---------------------------------------------------------------------------- Area Id Interface Neighbor id State 0.0.0.0 GigabitEthernet0/0/0 2.2.2.2 Full ----------------------------------------------------------------------------
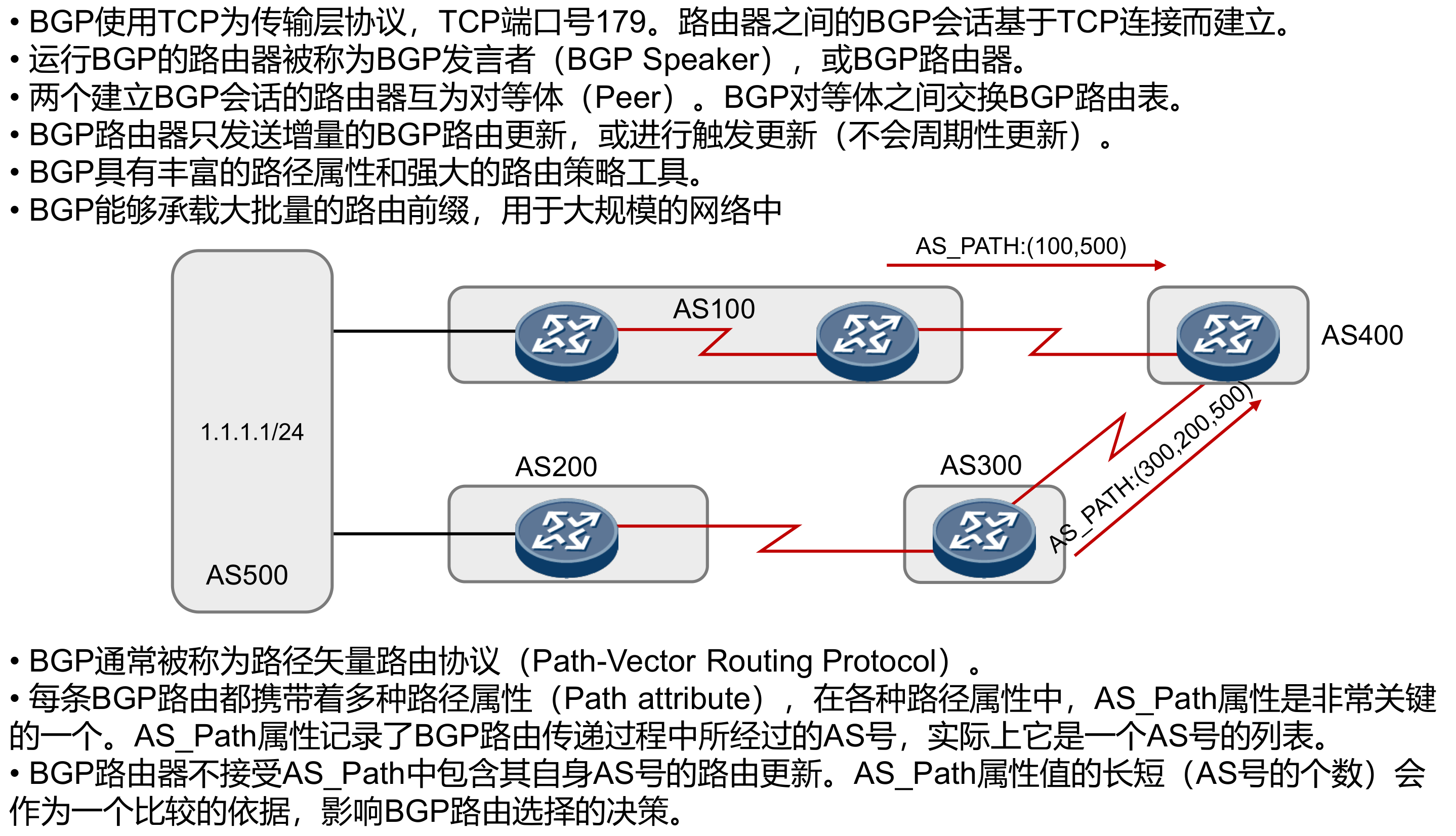
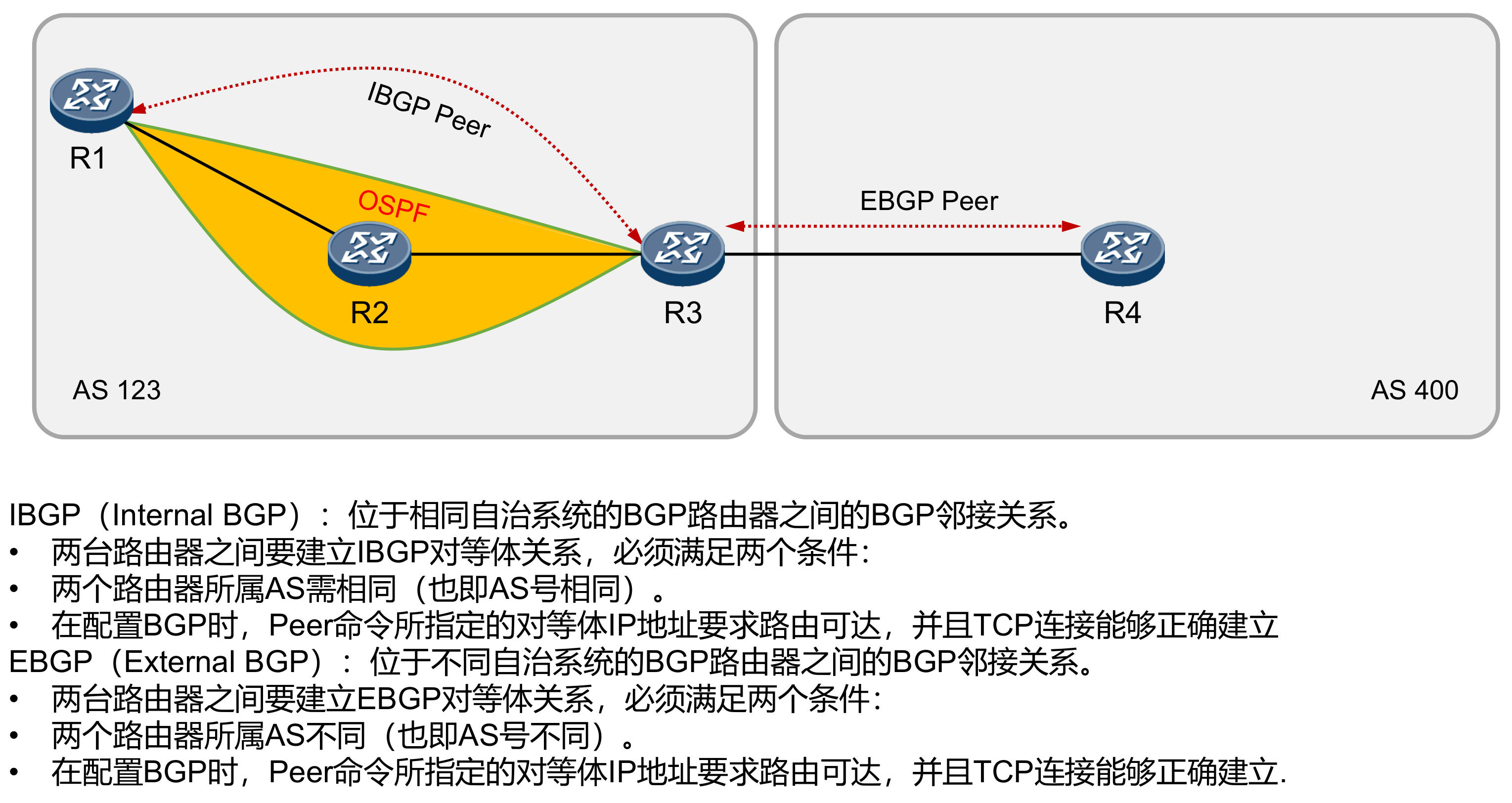
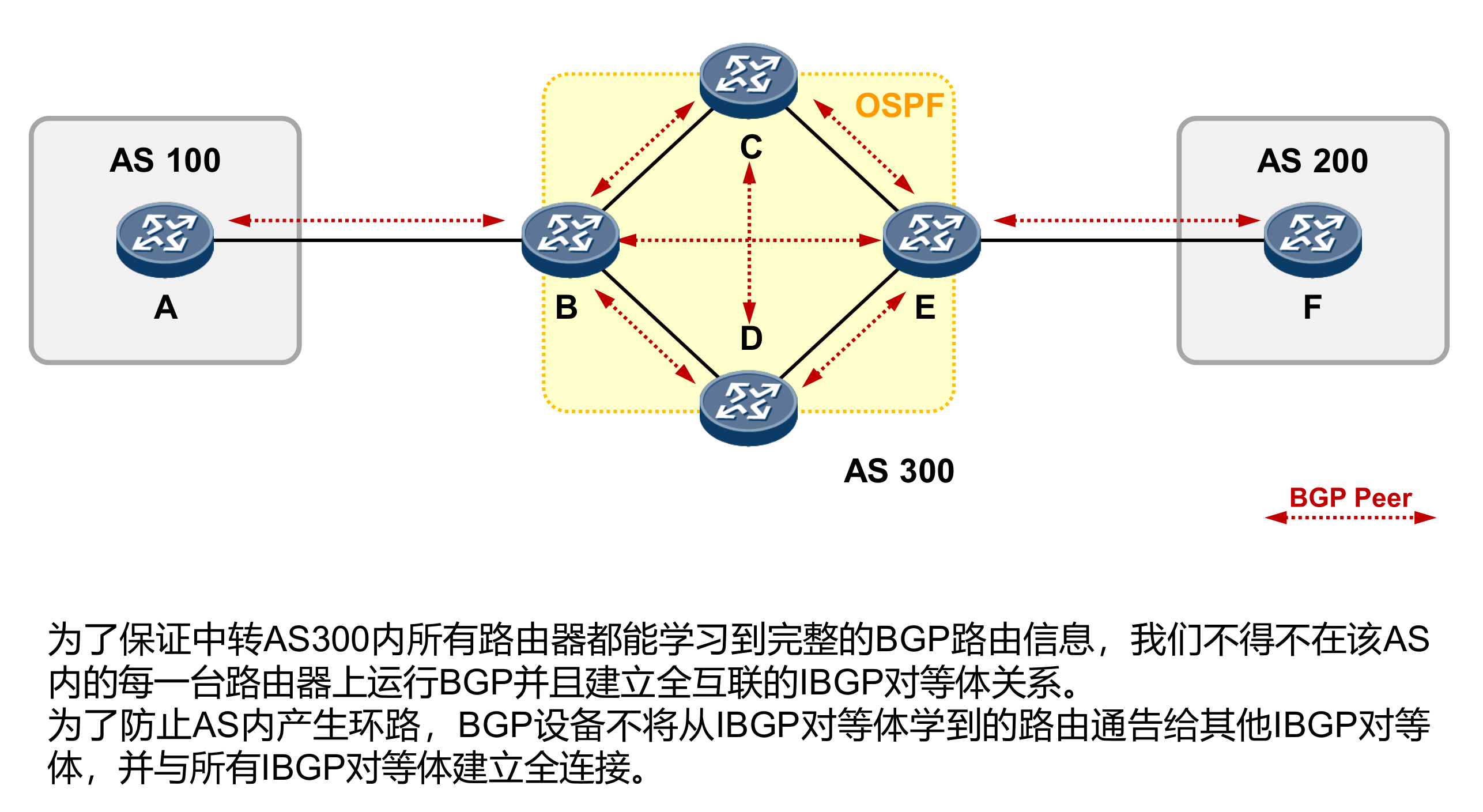
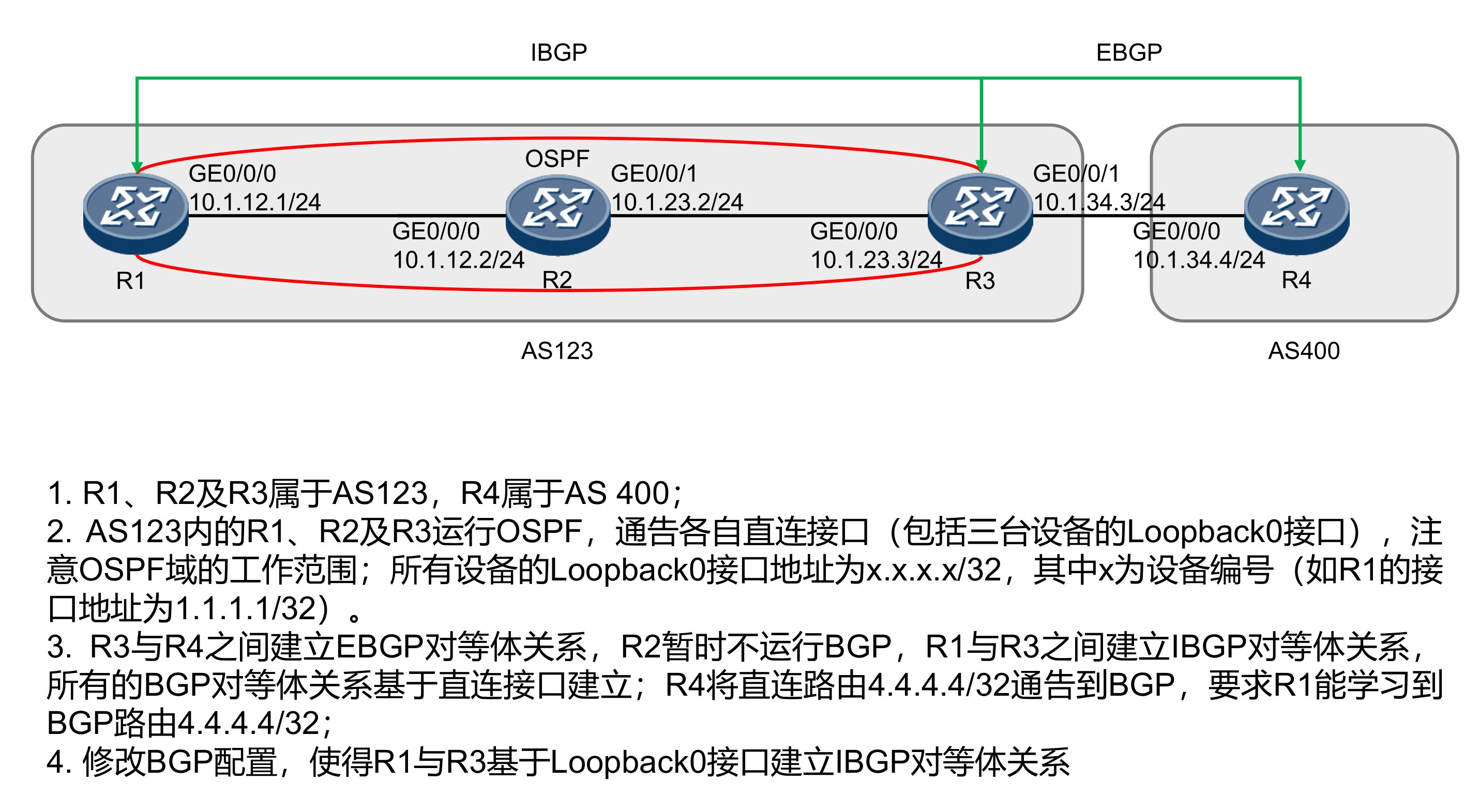
BGP Local router ID is 1.1.1.1 Status codes: * - valid, > - best, d - damped, h - history, i - internal, s - suppressed, S - Stale Origin : i - IGP, e - EGP, ? - incomplete
Total Number of Routes: 1 Network NextHop MED LocPrf PrefVal Path/Ogn
[AR4]bgp 400 [AR4-bgp]router-id 4.4.4.4 [AR4-bgp]peer 10.1.34.3 as-number 123 [AR4-bgp]dis bgp peer BGP local router ID : 4.4.4.4 LocalAS number : 400 Total number of peers : 1 Peers in established state : 1
Peer V AS MsgRcvd MsgSent OutQ Up/Down State Pre fRcv